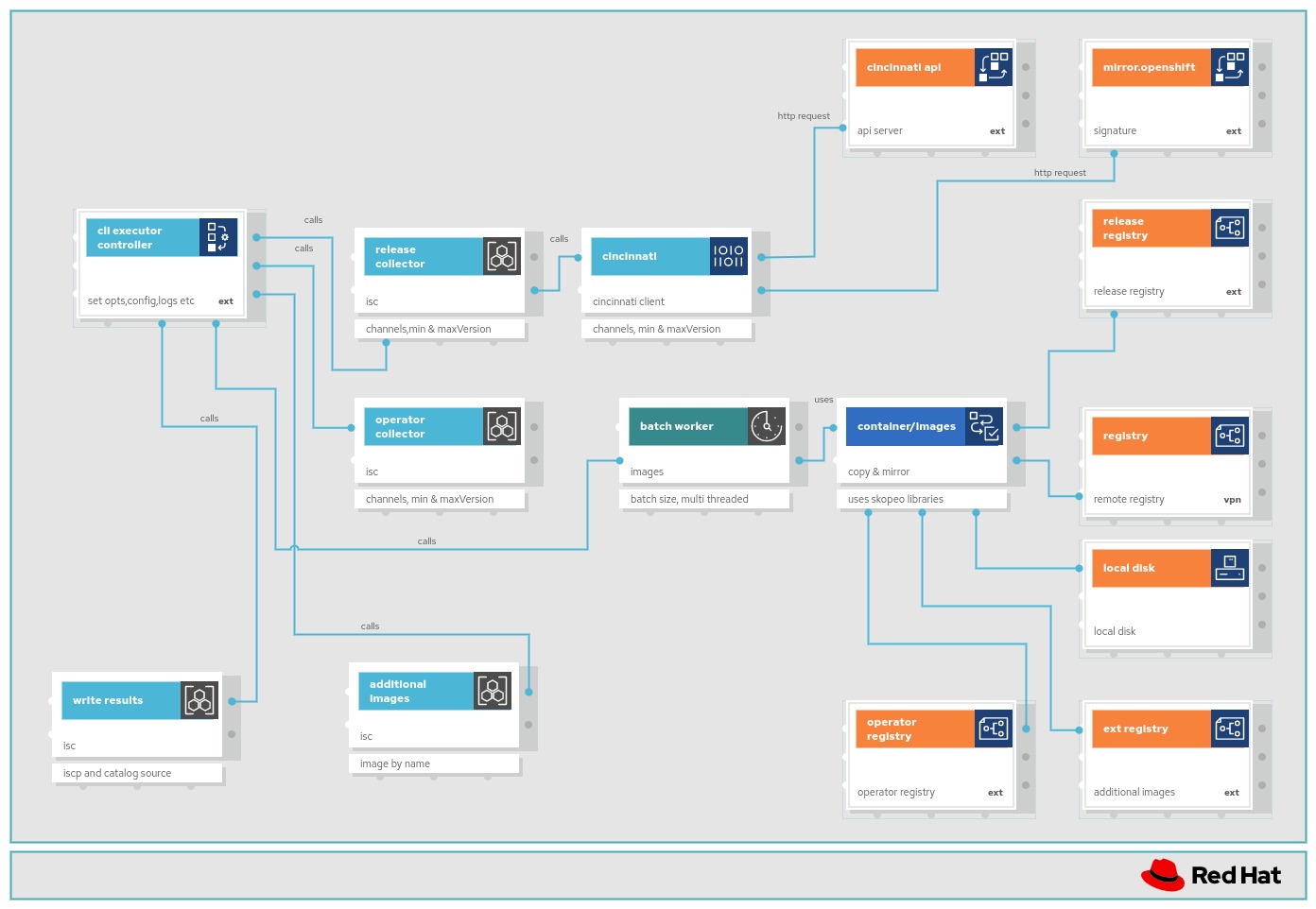
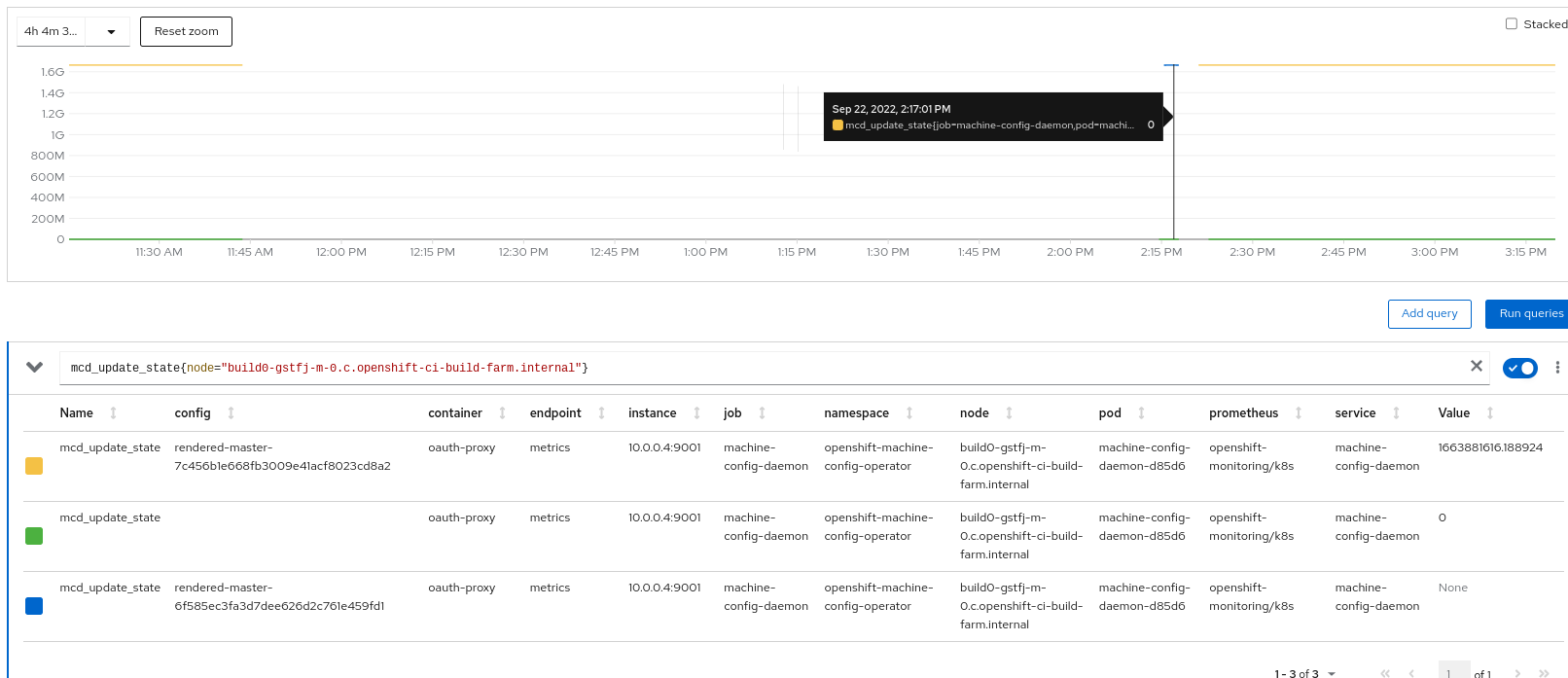
Complete Features
These features were completed when this image was assembled
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Complete during New status.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
 Design Doc:
Design Doc:
https://docs.google.com/document/d/1m6OYdz696vg1v8591v0Ao0_r_iqgsWjjM2UjcR_tIrM/
Problem:
Goal
As a developer, I want to be able to test my serverless function after it's been deployed.
Why is it important?
Use cases:
- As a developer, I want to test my serverless function
Acceptance criteria:
- This features needs to work in ACM (Multi cluster environment when console is being run on the Hub cluster)
Dependencies (External/Internal):
Please add a spike to see if there are dependencies.
Design Artifacts:
Exploration:
Developers can use the the kn func invoke CLI to accomplish this. According to Naina, there is an API, but it's in Go.
Note:
Description
As a user, I want to invoke a Serverless function from the developer console. This action should be available as a page and as a modal.
Acceptance Criteria
- A backend proxy to invoke a serverless function (or a k8s service in general) from the frontend without a public route.
- The API endpoint should be only accessible to logged-in users.
- Should also work when the bridge is running off-cluster (as developers start them mostly for local development)
Additional Details:
This will be similar to the web terminal proxy, except that no auth headers will be passed to the underlying service.
We need something similar to:
POST /proxy/in-cluster
{
endpoint: string
# Or just service: string ?? tbd.
headers: Record<string, string | string[]>
body: string
timeout: number
}
Description
As a user, I want to invoke a Serverless function from the developer console. This action should be available as a page and as a modal.
This story depends on ODC-7273, ODC-7274, and ODC-7288. This story should bring the backend proxy, and the frontend together and finalize the work.
Acceptance Criteria
- Write proper types if they are missed
- Connect the form and invoke a serverless function, consume and show the response
- Unit testes
- E2E tests
Additional Details:
Description
As a user, I want to invoke a Serverless function from the developer console. This action should be available as a page and as a modal.
This story is to evaluate a good UI for this and check this with our PM (Serena) and the Serverless team (Naina and Lance).
Acceptance Criteria
- Add a new page with title "Invoke Serverless function {function-name}" and should be available via a new URL (/serverless/ns/:ns/invoke-function/:function-name/).
- Implement a form with formik to "invoke" (console.log for now) Serverless functions, without writing the network call for this already. Focus on the UI to get feedback as early as possible. Use reusable, well-named components anyway.
- The page should be also available as a modal. Add a new action to all Serverless Services with the label (tbd) to open this modal from the Topology graph or from the Serverless Service list view.
- The page should have two tabs or two panes for the request and response. Each of this tabs/panes should have again two tabs, "similar" to the browser network inspector. See below for what we know currently.
- Get confirmation from Christoph, Serena, Naina, and Lance.
- Disable the action until we implement the network communication in
ODC-7275with the serverless function. - No e2e tests are needed for this story.
Additional Details:
Information the form should show:
- Request tab shows "Body" and "Options" tab
- Body is just a full size editor. We should reuse our code editor.
- Options contains:
- Auto complete text field “Content type” with placeholder “application/json”, that will be used when nothing is entered
- Dropdown “Format” with values “cloudevent” (default) and “http”
- Text field “Type” with placeholder text “boson.fn”, that will be used when nothing is entered
- Text field “Source” with placeholder “/boson/fn”, that will be used when nothing is entered
- Response tab shows Body and Info tab
- Body is a full size editor that shows the response. We should format a JSON string with JSON.stringify(data, null, 2)
- Info contains:
- Id (id)
- Type (type)
- Source (source)
- Time (time) (formatted)
- Content-Type: (datacontenttype)
< High-Level description of the feature ie: Executive Summary >
Goals
Cluster administrators need an in-product experience to discover and install new Red Hat offerings that can add high value to developer workflows.
Requirements
| Requirements | Notes | IS MVP |
| Discover new offerings in Home Dashboard | Y | |
| Access details outlining value of offerings | Y | |
| Access step-by-step guide to install offering | N | |
| Allow developers to easily find and use newly installed offerings | Y | |
| Support air-gapped clusters | Y |
< What are we making, for who, and why/what problem are we solving?>
Out of scope
Discovering solutions that are not available for installation on cluster
Dependencies
No known dependencies
Background, and strategic fit
Assumptions
None
Customer Considerations
Documentation Considerations
Quick Starts
What does success look like?
QE Contact
Impact
Related Architecture/Technical Documents
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
Problem:
Developers using Dev Console need to be made aware of the RH developer tooling available to them.
Goal:
Provide awareness to developers using Dev Console of the RH developer tooling that is available to them, including:
- odo
- OpenShift IDE extension, which is available on IntelliJ & VScode
- VSCode Knative IDE extension: https://marketplace.visualstudio.com/items?itemName=redhat.vscode-knative
- IntelliJ Knative Plugin: https://plugins.jetbrains.com/plugin/16476-knative--serverless-functions-by-red-hat
- Dev spaces
Consider enhancing the +Add page and/or the Guided tour
Provide a Quick Start for installing the Cryostat Operator
Why is it important?
To increase usage of our RH portfolio
Acceptance criteria:
- Quick Start - Installing Cryostat Operator
- Quick Start - Get started with JBoss EAP using a Helm Chart
- Discoverability of the IDE extensions from Create Serverless form
- Update Terminal step of the Guided Tour to indicate that odo CLI is accessible (link to https://developers.redhat.com/products/odo/overview)
Dependencies (External/Internal):
Design Artifacts:
Exploration:
Note:
Description
Add below IDE extensions in create serverless form,
- VSCode Knative IDE extension: https://marketplace.visualstudio.com/items?itemName=redhat.vscode-knative
- IntelliJ Knative Plugin: https://plugins.jetbrains.com/plugin/16476-knative--serverless-functions-by-red-hat
Acceptance Criteria
- In create serverless form add above IDE extensions
- On click of the link, user needs to take to respective pages
- Add e2e tests for that
Additional Details:
This issue is to handle the PR comment - https://github.com/openshift/console-operator/pull/770#pullrequestreview-1501727662 for the issue https://issues.redhat.com/browse/ODC-7292
Description
Update Terminal step of the Guided Tour to indicate that odo CLI is accessible - https://developers.redhat.com/products/odo/overview
Acceptance Criteria
- Update Guided tour of Web Terminal to add odo CLI link
- On click of link user has to redirected to respective page
Additional Details:
We are deprecating DeploymentConfig with Deployment in OpenShift because Deployment is the recommended way to deploy applications. Deployment is a more flexible and powerful resource that allows you to control the deployment of your applications more precisely. DeploymentConfig is a legacy resource that is no longer necessary. We will continue to support DeploymentConfig for a period of time, but we encourage you to migrate to Deployment as soon as possible.
Here are some of the benefits of using Deployment over DeploymentConfig:
- Deployment is more flexible. You can specify the number of replicas to deploy, the image to deploy, and the environment variables to use.
- Deployment is more powerful. You can use Deployment to roll out changes to your applications in a controlled manner.
- Deployment is the recommended way to deploy applications. OpenShift will continue to improve Deployment and make it the best way to deploy applications.
We hope that you will migrate to Deployment as soon as possible. If you have any questions, please contact us.
Epic Goal
- Make it possible to disable the DeploymentConfig and BuildConfig APIs, and associated controller logic.
Given the nature of this component (embedded into a shared api server and controller manager), this will likely require adding logic within those shared components to not enable specific bits of function when the build or DeploymentConfig capability is disabled, and watching the enabled capability set so that the components enable the functionality when necessary.
I would not expect us to split the components out of their existing location as part of this, though that is theoretically an option.
Why is this important?
- Reduces resource footprint and bug surface area for clusters that do not need to utilize the DeploymentConfig or BuildConfig functionality, such as SNO and OKE.
Acceptance Criteria (Mandatory)
- CI - MUST be running successfully with tests automated (we have an existing CI job that runs a cluster with all optional capabilities disabled. Passing that job will require disabling certain deploymentconfig tests when the cap is disabled)
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- Cluster install capabilities
Previous Work (Optional):
- The optional cap architecture and guidance for adding a new capability is described here: https://github.com/openshift/enhancements/blob/master/enhancements/installer/component-selection.md
Open questions::
None
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
Make the list of enabled/disable controllers in OAS reflect enabled/disabled capabilities.
Acceptance criteria:
- OAS allows to specify a list of enabled/disabled APIs (e.g. watches, caches, ...)
- OASO watches capabilities and generates the right configuration for OAS with enabled/disabled list of APIs
- Documentation is properly updated
QE:
- enabled/disable capabilities and validate a given API (DC, Builds, ...) is/is not managed by a cluster:
- checking the OAS logs do/do not log entries about affected API(s)
- DC/Builds objects are created/fail to be created
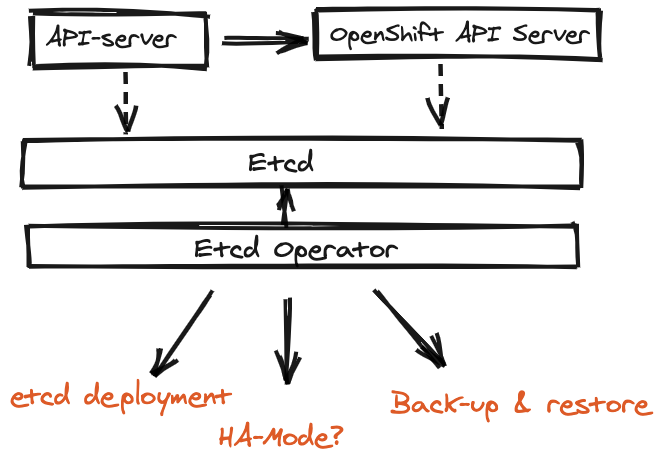
Feature Overview
At the moment, HyperShift is relying on an older etcd operator (i.e, the CoreOS etcd operator). However, this operator is basic and does not support HA as required.
Goals
Introduce a reliable component to operate Etcd that:
- Is backed up by a stable operator
- Supports Images with a Hash
- Supprts for Backups
- Local-persistent volumes for persistent data?
- Encryption.
- HA and Scalablity.
For an initial MVP of service delivery adoption of Hypershift we need to enable support for manual cluster migration.
Additional information: https://docs.google.com/presentation/d/1JDfd34jvj_4VvVn1bNieSXRejbFqAs_g8G-5rBqTtxw/edit?usp=sharing
Following on from https://issues.redhat.com/browse/HOSTEDCP-444 we need to add the steps to enable migration of the Node/CAPI resources to enable workloads to continue running during controlplane migration.
This will be a manual process where controlplane downtime will occur.
This must satisfy a successful migration criteria:
- All HC conditions are positive.
- All NodePool conditions are positive.
- All service endpoints kas/oauth/ignition server... are reachable.
- Ability to create/scale NodePools remains operational.
We need to validate and document this manually for starters.
Eventually this should be automated in the upcoming e2e test.
We could even have a job running conformance tests over a migrated cluster
Epic Goal
As an OpenShift on vSphere administrator, I want to specify static IP assignments to my VMs.
As an OpenShift on vSphere administrator, I want to completely avoid using a DHCP server for the VMs of my OpenShift cluster.
Why is this important?
Customers want the convenience of IPI deployments for vSphere without having to use DHCP. As in bare metal, where METAL-1 added this capability, some of the reasons are the security implications of DHCP (customers report that for example depending on configuration they allow any device to get in the network). At the same time IPI deployments only require to our OpenShift installation software, while with UPI they would need automation software that in secure environments they would have to certify along with OpenShift.
Acceptance Criteria
- I can specify static IPs for node VMs at install time with IPI
Previous Work
Bare metal related work:
METAL-1- https://github.com/openshift/enhancements/blob/master/enhancements/network/baremetal-ipi-network-configuration.md
CoreOS Afterburn:
https://github.com/coreos/afterburn/blob/main/src/providers/vmware/amd64.rs#L28
https://github.com/openshift/installer/blob/master/upi/vsphere/vm/main.tf#L34
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
As an OpenShift on vSphere administrator, I want to specify static IP assignments to my VMs.
As an OpenShift on vSphere administrator, I want to completely avoid using a DHCP server for the VMs of my OpenShift cluster.
Why is this important?
Customers want the convenience of IPI deployments for vSphere without having to use DHCP. As in bare metal, where METAL-1 added this capability, some of the reasons are the security implications of DHCP (customers report that for example depending on configuration they allow any device to get in the network). At the same time IPI deployments only require to our OpenShift installation software, while with UPI they would need automation software that in secure environments they would have to certify along with OpenShift.
Acceptance Criteria
- I can specify static IPs for node VMs at install time with IPI
Previous Work
Bare metal related work:
METAL-1- https://github.com/openshift/enhancements/blob/master/enhancements/network/baremetal-ipi-network-configuration.md
CoreOS Afterburn:
https://github.com/coreos/afterburn/blob/main/src/providers/vmware/amd64.rs#L28
https://github.com/openshift/installer/blob/master/upi/vsphere/vm/main.tf#L34
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
{}USER STORY:{}
As an OpenShift administrator, I want to apply an IP configuration so that I can adhere to my organizations security guidelines.
{}DESCRIPTION:{}
The vSphere machine controller needs to be modified to convert nmstate to `guestinfo.afterburn.initrd.network-kargs` upon cloning the template for a new machine. An example of this is here: https://github.com/openshift/machine-api-operator/pull/1079
{}Required:{}
- PR is approved
- Associated test(s) are created in https://github.com/openshift/cluster-api-actuator-pkg
{}Nice to have:{}
{}ACCEPTANCE CRITERIA:{}
{}ENGINEERING DETAILS:{}
Authentication-operator ignores noproxy settings defined in the cluster-wide proxy.
Expected outcome: When noproxy is set, Authentication operator should initialize connections through ingress instead of the cluster-wide proxy.
Background and Goal
Currently in OpenShift we do not support adding 3rd party agents and other software to cluster nodes. While rpm-ostree supports adding packages, we have no way today to do that in a sane, scalable way across machineconfigpools and clusters. Some customers may not be able to meet their IT policies due to this.
In addition to third party content, some customers may want to use the layering process as a point to inject configuration. The build process allows for simple copying of config files and the ability to run arbitrary scripts to set user config files (e.g. through an Ansible playbook). This should be a supported use case, except where it conflicts with OpenShift (for example, the MCO must continue to manage Cri-O and Kubelet configs).
Example Use Cases
- Bare metal firmware update software that is packaged as an RPM
- Host security monitors
- Forensic tools
- SEIM logging agents
- SSH Key management
- Device Drivers from OEM/ODM partners
Acceptance Criteria
- Administrators can deploy 3rd party repositories and packages to MachineConfigPools.
- Administrators can easily remove added packages and repository files.
- Administrators can manage system configuration files by copying files into the RHCOS build. [Note: if the same file is managed by the MCO, the MachineConfig version of the file is expected to "win" over the OS image version.]
Background
As part of enabling OCP CoreOS Layering for third party components, we will need to allow for package installation to /opt. Many OEMs and ISVs install to /opt and it would be difficult for them to make the change only for RHCOS. Meanwhile changing their RHEL target to a different target would also be problematic as their customers are expecting these tools to install in a certain way. Not having to worry about this path will provide the best ecosystem partner and customer experience.
Requirements
- Document how 3rd party vendors can be compatible with our current offering.
- Provide mechanism for 3rd party vendors or their customers to provide information for exceptions that require an RPM to install binaries to /opt as an install target path.
e2e test in our ci to override kernel
Possibly repurpose https://github.com/openshift/os/tree/master/tests/layering
Feature Overview (aka. Goal Summary)
Add support for custom security groups to be attached to control plane and compute nodes at installation time.
Goals (aka. expected user outcomes)
Allow the user to provide existing security groups to be attached to the control plane and compute node instances at installation time.
Requirements (aka. Acceptance Criteria):
The user will be able to provide a list of existing security groups to the install config manifest that will be used as additional custom security groups to be attached to the control plane and compute node instances at installation time.
Out of Scope
The installer won't be responsible of creating any custom security groups, these must be created by the user before the installation starts.
Background
We do have users/customers with specific requirements on adding additional network rules to every instance created in AWS. For OpenShift these additional rules need to be added on day-2 manually as the Installer doesn't provide the ability to add custom security groups to be attached to any instance at install time.
MachineSets already support adding a list of existing custom security groups, so this could be automated already at install time manually editing each MachineSet manifest before starting the installation, but even for these cases the Installer doesn't allow the user to provide this information to add the list of these security groups to the MachineSet manifests.
Documentation Considerations
Documentation will be required to explain how this information needs to be provided to the install config manifest as any other supported field.
Epic Goal
- Allow the user to provide existing security groups to be attached to the control plane and compute node instances at installation time.
Why is this important?
- We do have users/customers with specific requirements on adding additional network rules to every instance created in AWS. For OpenShift these additional rules need to be added on day-2 manually as the Installer doesn't provide the ability to add custom security groups to be attached to any instance at install time.
MachineSets already support adding a list of existing custom security groups, so this could be automated already at install time manually editing each MachineSet manifest before starting the installation, but even for these cases the Installer doesn't allow the user to provide this information to add the list of these security groups to the MachineSet manifests.
Scenarios
- The user will be able to provide a list of existing security groups to the install config that will be used as additional custom security groups to be attached to the control plane and compute node instances at installation time.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Previous Work (Optional):
- Compute Nodes managed by MAPI already support this feature
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Add custom security groups for compute nodes
- Add custom security groups for control plane nodes
so that I can achieve
- Control Plane and Compute nodes can support operational specific security rules. For instance: specific traffic may be required for compute vs control plane nodes.
Acceptance Criteria:
Description of criteria:
- The control plane and compute machine sections of the install config accept user input as additionalSecurityGroupIDs (when using the aws platform).
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
-
additionalSecurityGroupIDs: description: AdditionalSecurityGroupIDs contains IDs of additional security groups for machines, where each ID is presented in the format sg-xxxx. items: type: string type: array
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
Feature Overview (aka. Goal Summary)
Scaling of pod in Openshift highly depends on customer workload and their hardware setup . Some workloads on certain hardware might not scale beyond 100 pods and others might scale to 1000 pods .
As a openshift admin i want to monitor metrics that will indicate why i am not able to scale my pods . think of pressure gauge that will tell customer when its green ( can scale) when its red ( not scale)
As a openshift support team if a customer call in with their complain about pod scaling then i should be able to check some metrics and inform them why they are not able to scale
Goals (aka. expected user outcomes)
Metrics and alert and dashboard
Requirements (aka. Acceptance Criteria):
able to integrate these metrics and alert in a monitoring dashboard
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- To come up with set of metrics that indicate optimal node resource usage.
Why is this important?
- These metrics will help customers to understand the capacity they have instead of restricting themselves to hard coded max pod limit.
Scenarios
- As a owner of extremely high capacity machine, I want to be able to deploy as many pods as my machine can handle.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- None
Previous Work (Optional):
Open questions::
- The challenging part is come up with set of metrics that accurately indicate system resource usage.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
We need to have an operator to inject dashboard jsonnet. E.g. etcd team injects their dashboard jsonnet using their operator in the form of a config map.
We will need similar approach for node dashboard.
Feature Overview
Create a GCP cloud specific spec.resourceTags entry in the infrastructure CRD. This should create and update tags (or labels in GCP) on any openshift cloud resource that we create and manage. The behaviour should also tag existing resources that do not have the tags yet and once the tags in the infrastructure CRD are changed all the resources should be updated accordingly.
Tag deletes continue to be out of scope, as the customer can still have custom tags applied to the resources that we do not want to delete.
Due to the ongoing intree/out of tree split on the cloud and CSI providers, this should not apply to clusters with intree providers (!= "external").
Once confident we have all components updated, we should introduce an end2end test that makes sure we never create resources that are untagged.
Goals
- Functionality on GCP Tech Preview
- inclusion in the cluster backups
- flexibility of changing tags during cluster lifetime, without recreating the whole cluster
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
List any affected packages or components.
- Installer
- Cluster Infrastructure
- Storage
- Node
- NetworkEdge
- Internal Registry
- CCO
This epic covers the work to apply user defined labels GCP resources created for openshift cluster available as tech preview.
The user should be able to define GCP labels to be applied on the resources created during cluster creation by the installer and other operators which manages the specific resources. The user will be able to define the required tags/labels in the install-config.yaml while preparing with the user inputs for cluster creation, which will then be made available in the status sub-resource of Infrastructure custom resource which cannot be edited but will be available for user reference and will be used by the in-cluster operators for labeling when the resources are created.
Updating/deleting of labels added during cluster creation or adding new labels as Day-2 operation is out of scope of this epic.
List any affected packages or components.
- Installer
- Cluster Infrastructure
- Storage
- Node
- NetworkEdge
- Internal Registry
- CCO
Reference - https://issues.redhat.com/browse/RFE-2017
Enhancement proposed for Azure tags support in OCP, requires install-config CRD to be updated to include gcp userLabels for user to configure, which will be referred by the installer to apply the list of labels on each resource created by it and as well make it available in the Infrastructure CR created.
Below is the snippet of the change required in the CRD
apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: name: installconfigs.install.openshift.io spec: versions: - name: v1 schema: openAPIV3Schema: properties: platform: properties: gcp: properties: userLabels: additionalProperties: type: string description: UserLabels additional keys and values that the installer will add as labels to all resources that it creates. Resources created by the cluster itself may not include these labels. type: object
This change is required for testing the changes of the feature, and should ideally get merged first.
Acceptance Criteria
- Code linting, validation and best practices adhered to
- User should be able to configure gcp user defined labels in the install-config.yaml
- Fields descriptions
Enhancement proposed for GCP labels and tags support in OCP requires making use of latest APIs made available in terraform provider for google and requires an update to use the same.
Acceptance Criteria
- Code linting, validation and best practices adhered to.
Enhancement proposed for GCP tags support in OCP, requires cluster-image-registry-operator to add gcp userTags available in the status sub resource of infrastructure CR, to the gcp storage resource created.
cluster-image-registry-operator uses the method createStorageAccount() to create storage resource which should be updated to add tags after resource creation.
Acceptance Criteria
- Code linting, validation and best practices adhered to
- UTs and e2e are added/updated
cluster-config-operator makes Infrastructure CRD available for installer, which is included in it's container image from the openshift/api package and requires the package to be updated to have the latest CRD.
Installer creates below list of gcp resources during create cluster phase and these resources should be applied with the user defined labels and the default OCP label kubernetes-io-cluster-<cluster_id>:owned
Resources List
| Resource | Terraform API |
|---|---|
| VM Instance | google_compute_instance |
| Image | google_compute_image |
| Address | google_compute_address(beta) |
| ForwardingRule | google_compute_forwarding_rule(beta) |
| Zones | google_dns_managed_zone |
| Storage Bucket | google_storage_bucket |
Acceptance Criteria:
- Code linting, validation and best practices adhered to
- List of gcp resources created by installer should have user defined labels and as well as the default OCP label.
Enhancement proposed for GCP labels support in OCP, requires cluster-image-registry-operator to add gcp userLabels available in the status sub resource of infrastructure CR, to the gcp storage resource created.
cluster-image-registry-operator uses the method createStorageAccount() to create storage resource which should be updated to add labels.
Acceptance Criteria
- Code linting, validation and best practices adhered to
- UTs and e2e are added/updated
Enhancement proposed for GCP labels support in OCP, requires machine-api-provider-gcp to add azure userLabels available in the status sub resource of infrastructure CR, to the gcp virtual machines resource and the sub-resources created.
Acceptance Criteria
- Code linting, validation and best practices adhered to
- UTs and e2e are added/updated
Installer generates Infrastructure CR in manifests creation step of cluster creation process based on the user provided input recorded in install-config.yaml. While generating Infrastructure CR platformStatus.gcp.resourceLabels should be updated with the user provided labels(installconfig.platform.gcp.userLabels).
Acceptance Criteria
- Code linting, validation and best practices adhered to
- Infrastructure CR created by installer should have gcp user defined labels if any, in status field.
Feature Overview
Much like core OpenShift operators, a standardized flow exists for OLM-managed operators to interact with the cluster in a specific way to leverage AWS STS authorization when using AWS APIs as opposed to insecure static, long-lived credentials. OLM-managed operators can implement integration with the CloudCredentialOperator in well-defined way to support this flow.
Goals:
Enable customers to easily leverage OpenShift's capabilities around AWS STS with layered products, for increased security posture. Enable OLM-managed operators to implement support for this in well-defined pattern.
Requirements:
- CCO gets a new mode in which it can reconcile STS credential request for OLM-managed operators
- A standardized flow is leveraged to guide users in discovering and preparing their AWS IAM policies and roles with permissions that are required for OLM-managed operators
- A standardized flow is defined in which users can configure OLM-managed operators to leverage AWS STS
- An example operator is used to demonstrate the end2end functionality
- Clear instructions and documentation for operator development teams to implement the required interaction with the CloudCredentialOperator to support this flow
Use Cases:
See Operators & STS slide deck.
Out of Scope:
- handling OLM-managed operator updates in which AWS IAM permission requirements might change from one version to another (which requires user awareness and intervention)
Background:
The CloudCredentialsOperator already provides a powerful API for OpenShift's cluster core operator to request credentials and acquire them via short-lived tokens. This capability should be expanded to OLM-managed operators, specifically to Red Hat layered products that interact with AWS APIs. The process today is cumbersome to none-existent based on the operator in question and seen as an adoption blocker of OpenShift on AWS.
Customer Considerations
This is particularly important for ROSA customers. Customers are expected to be asked to pre-create the required IAM roles outside of OpenShift, which is deemed acceptable.
Documentation Considerations
- Internal documentation needs to exists to guide Red Hat operator developer teams on the requirements and proposed implementation of integration with CCO and the proposed flow
- External documentation needs to exist to guide users on:
- how to become aware that the cluster is in STS mode
- how to become aware of operators that support STS and the proposed CCO flow
- how to become aware of the IAM permissions requirements of these operators
- how to configure an operator in the proposed flow to interact with CCO
Interoperability Considerations
- this needs to work with ROSA
- this needs to work with self-managed OCP on AWS
Market Problem
This Section: High-Level description of the Market Problem ie: Executive Summary
- As a customer of OpenShift layered products, I need to be able to fluidly, reliably and consistently install and use OpenShift layered product Kubernetes Operators into my ROSA STS clusters, while keeping a STS workflow throughout.
- As a customer of OpenShift on the big cloud providers, overall I expect OpenShift as a platform to function equally well with tokenized cloud auth as it does with "mint-mode" IAM credentials. I expect the same from the Kubernetes Operators under the Red Hat brand (that need to reach cloud APIs) in that tokenized workflows are equally integrated and workable as with "mint-mode" IAM credentials.
- As the managed services, including Hypershift teams, offering a downstream opinionated, supported and managed lifecycle of OpenShift (in the forms of ROSA, ARO, OSD on GCP, Hypershift, etc), the OpenShift platform should have as close as possible, native integration with core platform operators when clusters use tokenized cloud auth, driving the use of layered products.
- .
- As the Hypershift team, where the only credential mode for clusters/customers is STS (on AWS) , the Red Hat branded Operators that must reach the AWS API, should be enabled to work with STS credentials in a consistent, and automated fashion that allows customer to use those operators as easily as possible, driving the use of layered products.
Why it Matters
- Adding consistent, automated layered product integrations to OpenShift would provide great added value to OpenShift as a platform, and its downstream offerings in Managed Cloud Services and related offerings.
- Enabling Kuberenetes Operators (at first, Red Hat ones) on OpenShift for the "big3" cloud providers is a key differentiation and security requirement that our customers have been and continue to demand.
- HyperShift is an STS-only architecture, which means that if our layered offerings via Operators cannot easily work with STS, then it would be blocking us from our broad product adoption goals.
Illustrative User Stories or Scenarios
- Main success scenario - high-level user story
- customer creates a ROSA STS or Hypershift cluster (AWS)
- customer wants basic (table-stakes) features such as AWS EFS or RHODS or Logging
- customer sees necessary tasks for preparing for the operator in OperatorHub from their cluster
- customer prepares AWS IAM/STS roles/policies in anticipation of the Operator they want, using what they get from OperatorHub
- customer's provides a very minimal set of parameters (AWS ARN of role(s) with policy) to the Operator's OperatorHub page
- The cluster can automatically setup the Operator, using the provided tokenized credentials and the Operator functions as expected
- Cluster and Operator upgrades are taken into account and automated
- The above steps 1-7 should apply similarly for Google Cloud and Microsoft Azure Cloud, with their respective token-based workload identity systems.
- Alternate flow/scenarios - high-level user stories
- The same as above, but the ROSA CLI would assist with AWS role/policy management
- The same as above, but the oc CLI would assist with cloud role/policy management (per respective cloud provider for the cluster)
- ...
Expected Outcomes
This Section: Articulates and defines the value proposition from a users point of view
- See SDE-1868 as an example of what is needed, including design proposed, for current-day ROSA STS and by extension Hypershift.
- Further research is required to accomodate the AWS STS equivalent systems of GCP and Azure
- Order of priority at this time is
- 1. AWS STS for ROSA and ROSA via HyperShift
- 2. Microsoft Azure for ARO
- 3. Google Cloud for OpenShift Dedicated on GCP
Effect
This Section: Effect is the expected outcome within the market. There are two dimensions of outcomes; growth or retention. This represents part of the “why” statement for a feature.
- Growth is the acquisition of net new usage of the platform. This can be new workloads not previously able to be supported, new markets not previously considered, or new end users not previously served.
- Retention is maintaining and expanding existing use of the platform. This can be more effective use of tools, competitive pressures, and ease of use improvements.
- Both of growth and retention are the effect of this effort.
- Customers have strict requirements around using only token-based cloud credential systems for workloads in their cloud accounts, which include OpenShift clusters in all forms.
- We gain new customers from both those that have waited for token-based auth/auth from OpenShift and from those that are new to OpenShift, with strict requirements around cloud account access
- We retain customers that are going thru both cloud-native and hybrid-cloud journeys that all inevitably see security requirements driving them towards token-based auth/auth.
- Customers have strict requirements around using only token-based cloud credential systems for workloads in their cloud accounts, which include OpenShift clusters in all forms.
References
As an engineer I want the capability to implement CI test cases that run at different intervals, be it daily, weekly so as to ensure downstream operators that are dependent on certain capabilities are not negatively impacted if changes in systems CCO interacts with change behavior.
Acceptance Criteria:
Create a stubbed out e2e test path in CCO and matching e2e calling code in release such that there exists a path to tests that verify working in an AWS STS workflow.
OC mirror is GA product as of Openshift 4.11 .
The goal of this feature is to solve any future customer request for new features or capabilities in OC mirror
In 4.12 release, a new feature was introduced to oc-mirror allowing it to use OCI FBC catalogs as starting point for mirroring operators.
Overview
As a oc-mirror user, I would like the OCI FBC feature to be stable
so that I can use it in a production ready environment
and to make the new feature and all existing features of oc-mirror seamless
Current Status
This feature is ring-fenced in the oc mirror repository, it uses the following flags to achieve this so as not to cause any breaking changes in the current oc-mirror functionality.
- --use-oci-feature
- --oci-feature-action (copy or mirror)
- --oci-registries-config
The OCI FBC (file base container) format has been delivered for Tech Preview in 4.12
Tech Enablement slides can be found here https://docs.google.com/presentation/d/1jossypQureBHGUyD-dezHM4JQoTWPYwiVCM3NlANxn0/edit#slide=id.g175a240206d_0_7
Design doc is in https://docs.google.com/document/d/1-TESqErOjxxWVPCbhQUfnT3XezG2898fEREuhGena5Q/edit#heading=h.r57m6kfc2cwt (also contains latest design discussions around the stories of this epic)
Link to previous working epic https://issues.redhat.com/browse/CFE-538
Contacts for the OCI FBC feature
- Sherine Khoury
- Luigi Mario Zuccarelli
- IBM John Hunkins
- CFE PM Heather Heffner
- WRKLDS PM Tomas Smetana
Feature Overview (aka. Goal Summary)
The OpenShift Assisted Installer is a user-friendly OpenShift installation solution for the various platforms, but focused on bare metal. This very useful functionality should be made available for the IBM zSystem platform.
Goals (aka. expected user outcomes)
Use of the OpenShift Assisted Installer to install OpenShift on an IBM zSystem
Requirements (aka. Acceptance Criteria):
Using the OpenShift Assisted Installer to install OpenShift on an IBM zSystem
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
As a multi-arch development engineer, I would like to ensure that the Assisted Installer workflow is fully functional and supported for z/VM deployments.
Acceptance Criteria
- Feature is implemented, tested, QE, documented, and technically enabled.
- Stories closed.
Description of the problem:
Using FCP (multipath) devices for zVM node
parmline:
rd.neednet=1 console=ttysclp0 coreos.live.rootfs_url=http://172.23.236.156:8080/assisted-installer/rootfs.img ip=10.14.6.8::10.14.6.1:255.255.255.0:master-0:encbdd0:none nameserver=10.14.6.1 ip=[fd00::8]::[fd00::1]:64::encbdd0:none nameserver=[fd00::1] zfcp.allow_lun_scan=0 rd.znet=qeth,0.0.bdd0,0.0.bdd1,0.0.bdd2,layer2=1 rd.zfcp=0.0.8007,0x500507630400d1e3,0x4000401e00000000 rd.zfcp=0.0.8107,0x50050763040851e3,0x4000401e00000000 random.trust_cpu=on rd.luks.options=discard ignition.firstboot ignition.platform.id=metal console=tty1 console=ttyS1,115200n8
shows disk limitation error in the UI.
<see attached image>
How reproducible:
Attach two FCP devices to a zVM node. Create a cluster and boot zVM node into discovery service. Host discovery panel shows an error for discovered host.
Steps to reproduce:
1. Attach two FCP devices to the zVM.
2. Create new cluster using the AI UI and configure discovery image
3. Boot zVM node
4. Waiting until node is showing up on the Host discovery panel.
5. FCP devices are not recognized as valid option
Actual results:
FCP devices can't be used as installable disk
Expected results:
FCP device can be used for installation (multipath must be activated after installation:
https://docs.openshift.com/container-platform/4.13/post_installation_configuration/ibmz-post-install.html#enabling-multipathing-fcp-luns_post-install-configure-additional-devices-ibmz)
Discovering an regression on staging where default is set to minimal ISO preventing installation of OCP 4.13 for s390x architecture.
See following older bugs addressing the same issue I guess

Description of the problem:
Using DASD devices are not recognized correctly if attached and used for a zVM node.
<see attached screenshot>
Attach two FCP devices to a zVM node. Create a cluster and boot zVM node into discovery service. Host discovery panel shows an error for discovered host.
Steps to reproduce:
1. Attach two DASD devices to the zVM.
2. Create new cluster using the AI UI and configure discovery image
3. Boot zVM node
4. Waiting until node is showing up on the Host discovery panel.
5. DASD devices are not recognized as valid option
Actual results:
DASD devices can't be used as installable disk
Expected results:
DASD device can be used for installation. User can choose the on which device AI will install to.
Epic Goal
As an OpenShift infrastructure owner I need to deploy OCP on OpenStack with the installer-provisioned infrastructure workflow and configure my own load balancers
Why is this important?
Customers want to use their own load balancers and IPI comes with built-in LBs based in keepalived and haproxy.
Scenarios
- A large deployment routed across multiple failure domains without stretched L2 networks, would require to dynamically route the control plane VIP traffic through load-balancers capable of living in multiple L2.
- Customers who want to use their existing LB appliances for the control plane.
Acceptance Criteria
- Should we require the support of migration from internal to external LB?
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- QE - must be testing a scenario where we disable the internal LB and setup an external LB and OCP deployment is running fine.
- Documentation - we need to document all the gotchas regarding this type of deployment, even the specifics about the load-balancer itself (routing policy, dynamic routing, etc)
Dependencies (internal and external)
- Fixed IPs would be very interesting to support, already WIP by vsphere (need to Spike on this): https://issues.redhat.com/browse/OCPBU-179
- Confirm with customers that they are ok with external LB or they prefer a new internal LB that supports BGP
Previous Work:
vsphere has done the work already via https://issues.redhat.com/browse/SPLAT-409
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
As an OpenShift infrastructure owner I need to deploy OCP on OpenStack with the installer-provisioned infrastructure workflow and configure my own load balancers
Why is this important?
Customers want to use their own load balancers and IPI comes with built-in LBs based in keepalived and haproxy.
Scenarios
- A large deployment routed across multiple failure domains without stretched L2 networks, would require to dynamically route the control plane VIP traffic through load-balancers capable of living in multiple L2.
- Customers who want to use their existing LB appliances for the control plane.
Acceptance Criteria
- Should we require the support of migration from internal to external LB?
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- QE - must be testing a scenario where we disable the internal LB and setup an external LB and OCP deployment is running fine.
- Documentation - we need to document all the gotchas regarding this type of deployment, even the specifics about the load-balancer itself (routing policy, dynamic routing, etc)
Dependencies (internal and external)
- Fixed IPs would be very interesting to support, already WIP by vsphere (need to Spike on this): https://issues.redhat.com/browse/OCPBU-179
- Confirm with customers that they are ok with external LB or they prefer a new internal LB that supports BGP
Previous Work:
vsphere has done the work already via https://issues.redhat.com/browse/SPLAT-409
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Notes: https://github.com/EmilienM/ansible-role-routed-lb is an example of a LB that will be used for CI, can be used by QE and customers.
Epic Goal
As an OpenShift infrastructure owner I need to deploy OCP on OpenStack with the installer-provisioned infrastructure workflow and configure my own load balancers
Why is this important?
Customers want to use their own load balancers and IPI comes with built-in LBs based in keepalived and haproxy.
Scenarios
- A large deployment routed across multiple failure domains without stretched L2 networks, would require to dynamically route the control plane VIP traffic through load-balancers capable of living in multiple L2.
- Customers who want to use their existing LB appliances for the control plane.
Acceptance Criteria
- Should we require the support of migration from internal to external LB?
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- QE - must be testing a scenario where we disable the internal LB and setup an external LB and OCP deployment is running fine.
- Documentation - we need to document all the gotchas regarding this type of deployment, even the specifics about the load-balancer itself (routing policy, dynamic routing, etc)
Dependencies (internal and external)
- Fixed IPs would be very interesting to support, already WIP by vsphere (need to Spike on this): https://issues.redhat.com/browse/OCPBU-179
- Confirm with customers that they are ok with external LB or they prefer a new internal LB that supports BGP
Previous Work:
vsphere has done the work already via https://issues.redhat.com/browse/SPLAT-409
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
- Support OpenShift to be deployed on AWS Local Zones
Goals
- Support OpenShift to be deployed from day-0 on AWS Local Zones
- Support an existing OpenShift cluster to deploy compute Nodes on AWS Local Zones (day-2)
AWS Local Zones support - feature delivered in phases:
- Phase 0 (
OCPPLAN-9630): Document how to create compute nodes on AWS Local Zones in day-0 (SPLAT-635) - Phase 1 (
OCPBU-2): Create edge compute pool to generate MachineSets for node with NoSchedule taints when installing a cluster in existing VPC with AWS Local Zone subnets (SPLAT-636) - Phase 2 (
OCPBU-351): Installer automates network resources creation on Local Zone based on the edge compute pool (SPLAT-657)
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
<!--
Please make sure to fill all story details here with enough information so
that it can be properly sized and is immediately actionable. Our Definition
of Ready for user stories is detailed in the link below:
https://docs.google.com/document/d/1Ps9hWl6ymuLOAhX_-usLmZIP4pQ8PWO15tMksh0Lb_A/
As much as possible, make sure this story represents a small chunk of work
that could be delivered within a sprint. If not, consider the possibility
of splitting it or turning it into an epic with smaller related stories.
Before submitting it, please make sure to remove all comments like this one.
-->
{}USER STORY:{}
<!--
One sentence describing this story from an end-user perspective.
-->
As a [type of user], I want [an action] so that [a benefit/a value].
{}DESCRIPTION:{}
<!--
Provide as many details as possible, so that any team member can pick it up
and start to work on it immediately without having to reach out to you.
-->
{}Required:{}
...
{}Nice to have:{}
...
{}ACCEPTANCE CRITERIA:{}
<!--
Describe the goals that need to be achieved so that this story can be
considered complete. Note this will also help QE to write their acceptance
tests.
-->
{}ENGINEERING DETAILS:{}
<!--
Any additional information that might be useful for engineers: related
repositories or pull requests, related email threads, GitHub issues or
other online discussions, how to set up any required accounts and/or
environments if applicable, and so on.
-->
Feature Overview
Testing is one of the main pillars of production-grade software. It helps validate and flag issues early on before the code is shipped into productive landscapes. Code changes no matter how small they are might lead to bugs and outages, the best way to validate bugs is to write proper tests, and to run those tests we need to have a foundation for a test infrastructure, finally, to close the circle, automation of these tests and their corresponding build help reduce errors and save a lot of time.
Goal(s)
- How do we get infrastructure, what infrastructure accounts are required?
- Build e2e integration with openshift-release on AWS.
- Define MVP CI Jobs to validate (e.g., conformance). What tests are failing, are we skipping any? why?
Note: Sync with the Developer productivity teams might be required to understand infra requirements especially for our first HyperShift infrastructure backend, AWS.
Context:
This is a placeholder epic to capture all the e2e scenarios that we want to test in CI in the long term. Anything which is a TODO here should at minimum be validated by QE as it is developed.
DoD:
Every supported scenario is e2e CI tested.
Scenarios:
- Hypershift deployment with services as routes.
- Hypershift deployment with services as NodePorts.
DoD:
Refactor the E2E tests following new pattern with 1 HostedCluster and targeted NodePools:
- nodepool_upgrade_test.go
Goal
Productize agent-installer-utils container from https://github.com/openshift/agent-installer-utils
Feature Description
In order to ship the network reconfiguration it would be useful to move the agent-tui to its own image instead of sharing the agent-installer-node-agent one.
Goal
Productize agent-installer-utils container from https://github.com/openshift/agent-installer-utils
Feature Description
In order to ship the network reconfiguration it would be useful to move the agent-tui to its own image instead of sharing the agent-installer-node-agent one.
Currently the `agent create image` command takes care to extract the agent-tui binary (and required libs) from the `assisted-installer-agent` image (shipped in the release as `agent-installer-node-agent`).
Once the agent-tui will be available instead from the `agent-installer-utils` image, it would be necessary to update accordingly the installer code (see https://github.com/openshift/installer/blob/56e85bee78490c18aaf33994e073cbc16181f66d/pkg/asset/agent/image/agentimage.go#L81)
agent-tui is currently built and shipped using the assisted-installer-agent repo. Since it will be move into its own repository (agent-installer-utils), it's necessary to cleanup the previous code.
- Remove agent-tui and nmstate dependencies from Docker image (https://github.com/openshift/assisted-installer-agent/blob/master/Dockerfile.ocp)
- Remove source (and vendored code) (https://github.com/openshift/assisted-installer-agent/tree/master/src/agent_tui)
Feature Overview
Allow users to interactively adjust the network configuration for a host after booting the agent ISO.
Goals
Configure network after host boots
The user has Static IPs, VLANs, and/or bonds to configure, but has no idea of the device names of the NICs. They don't enter any network config in agent-config.yaml. Instead they configure each host's network via the text console after it boots into the image.
Epic Goal
- Allow users to interactively adjust the network configuration for a host after booting the agent ISO, before starting processes that pull container images.
Why is this important?
- Configuring the network prior to booting a host is difficult and error-prone. Not only is the nmstate syntax fairly arcane, but the advent of 'predictable' interface names means that interfaces retain the same name across reboots but it is nearly impossible to predict what they will be. Applying configuration to the correct hosts requires correct knowledge and input of MAC addresses. All of these present opportunities for things to go wrong, and when they do the user is forced to return to the beginning of the process and generate a new ISO, then boot all of the hosts in the cluster with it again.
Scenarios
- The user has Static IPs, VLANs, and/or bonds to configure, but has no idea of the device names of the NICs. They don't enter any network config in agent-config.yaml. Instead they configure each host's network via the text console after it boots into the image.
- The user has Static IPs, VLANs, and/or bonds to configure, but makes an error entering the configuration in agent-config.yaml so that (at least) one host will not be able to pull container images from the release payload. They correct the configuration for that host via the text console before proceeding with the installation.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Currently the agent-tui displays always the additional checks (nslookup/ping/http get), even when the primary check (pull image) passes. This may cause some confusion to the user, due the fact that the additional checks do not prevent the agent-tui to complete successfully but they are just informative, to allow a better troubleshooting of the issue (so not needed in the positive case).
The additional checks should then be shown only when the primary check fails for any reason.
When the UI is active in the console events messages that are generated will distort the interface and make it difficult for the user to view the configuration and select options. An example is shown in the attached screenshot.
When the agent-tui is shown during the initial host boot, if the pull release image check fails then an additional checks box is shown along with a details text view.
The content of the details view gets continuosly updated with the details of failed check, but the user cannot move the focus over the details box (using the arrow/tab keys), thus cannot scroll its content (using the up/down arrow keys)
The openshift-install agent create image will need to fetch the agent-tui executable so that it could be embedded within the agent ISO. For this reason the agent-tui must be available in the release payload, so that it could be retrieved even when the command is invoked in a disconnected environment.
Epic Goal
Full support of North-South (cluster egress-ingress) IPsec that shares an encryption back-end with the current East-West implementation, allows for IPsec offload to capable SmartNICs, can be enabled and disabled at runtime, and allows for FIPS compliance (including install-time configuration and disabling of runtime configuration).
Why is this important?
- Customers went end-to-end default encryption with external servers and/or clients.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Must allow for the possibility of offloading the IPsec encryption to a SmartNIC.
Dependencies (internal and external)
Related:
- ITUP-44 - OpenShift support for North-South OVN IPSec
HATSTRAT-33- Encrypt All Traffic to/from Cluster (aka IPSec as a Service)
Previous Work (Optional):
SDN-717- Support IPSEC on ovn-kubernetes
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This is a clone of issue OCPBUGS-17380. The following is the description of the original issue:
—
Description of problem:
Enable IPSec pre/post install on OVN IC cluster
$ oc patch networks.operator.openshift.io cluster --type=merge -p '{"spec":{"defaultNetwork":{"ovnKubernetesConfig":{"ipsecConfig":{ }}}}}'
network.operator.openshift.io/cluster patched
ovn-ipsec containers complaining:
ovs-monitor-ipsec | ERR | Failed to import certificate into NSS.
b'certutil: unable to open "/etc/openvswitch/keys/ipsec-cacert.pem" for reading (-5950, 2).\n'
$ oc rsh ovn-ipsec-d7rx9
Defaulted container "ovn-ipsec" out of: ovn-ipsec, ovn-keys (init)
sh-5.1# certutil -L -d /var/lib/ipsec/nss Certificate Nickname Trust Attributes
SSL,S/MIME,JAR/XPIovs_certkey_db961f9a-7de4-4f1d-a2fb-a8306d4079c5 u,u,u
sh-5.1# cat /var/log/openvswitch/libreswan.log
Aug 4 15:12:46.808394: Initializing NSS using read-write database "sql:/var/lib/ipsec/nss"
Aug 4 15:12:46.837350: FIPS Mode: NO
Aug 4 15:12:46.837370: NSS crypto library initialized
Aug 4 15:12:46.837387: FIPS mode disabled for pluto daemon
Aug 4 15:12:46.837390: FIPS HMAC integrity support [disabled]
Aug 4 15:12:46.837541: libcap-ng support [enabled]
Aug 4 15:12:46.837550: Linux audit support [enabled]
Aug 4 15:12:46.837576: Linux audit activated
Aug 4 15:12:46.837580: Starting Pluto (Libreswan Version 4.9 IKEv2 IKEv1 XFRM XFRMI esp-hw-offload FORK PTHREAD_SETSCHEDPRIO GCC_EXCEPTIONS NSS (IPsec profile) (NSS-KDF) DNSSEC SYSTEMD_WATCHDOG LABELED_IPSEC (SELINUX) SECCOMP LIBCAP_NG LINUX_AUDIT AUTH_PAM NETWORKMANAGER CURL(non-NSS) LDAP(non-NSS)) pid:147
Aug 4 15:12:46.837583: core dump dir: /run/pluto
Aug 4 15:12:46.837585: secrets file: /etc/ipsec.secrets
Aug 4 15:12:46.837587: leak-detective enabled
Aug 4 15:12:46.837589: NSS crypto [enabled]
Aug 4 15:12:46.837591: XAUTH PAM support [enabled]
Aug 4 15:12:46.837604: initializing libevent in pthreads mode: headers: 2.1.12-stable (2010c00); library: 2.1.12-stable (2010c00)
Aug 4 15:12:46.837664: NAT-Traversal support [enabled]
Aug 4 15:12:46.837803: Encryption algorithms:
Aug 4 15:12:46.837814: AES_CCM_16 {256,192,*128} IKEv1: ESP IKEv2: ESP FIPS aes_ccm, aes_ccm_c
Aug 4 15:12:46.837820: AES_CCM_12 {256,192,*128} IKEv1: ESP IKEv2: ESP FIPS aes_ccm_b
Aug 4 15:12:46.837826: AES_CCM_8 {256,192,*128} IKEv1: ESP IKEv2: ESP FIPS aes_ccm_a
Aug 4 15:12:46.837831: 3DES_CBC [*192] IKEv1: IKE ESP IKEv2: IKE ESP FIPS NSS(CBC) 3des
Aug 4 15:12:46.837837: CAMELLIA_CTR {256,192,*128} IKEv1: ESP IKEv2: ESP
Aug 4 15:12:46.837843: CAMELLIA_CBC {256,192,*128} IKEv1: IKE ESP IKEv2: IKE ESP NSS(CBC) camellia
Aug 4 15:12:46.837849: AES_GCM_16 {256,192,*128} IKEv1: ESP IKEv2: IKE ESP FIPS NSS(GCM) aes_gcm, aes_gcm_c
Aug 4 15:12:46.837855: AES_GCM_12 {256,192,*128} IKEv1: ESP IKEv2: IKE ESP FIPS NSS(GCM) aes_gcm_b
Aug 4 15:12:46.837861: AES_GCM_8 {256,192,*128} IKEv1: ESP IKEv2: IKE ESP FIPS NSS(GCM) aes_gcm_a
Aug 4 15:12:46.837867: AES_CTR {256,192,*128} IKEv1: IKE ESP IKEv2: IKE ESP FIPS NSS(CTR) aesctr
Aug 4 15:12:46.837872: AES_CBC {256,192,*128} IKEv1: IKE ESP IKEv2: IKE ESP FIPS NSS(CBC) aes
Aug 4 15:12:46.837878: NULL_AUTH_AES_GMAC {256,192,*128} IKEv1: ESP IKEv2: ESP FIPS aes_gmac
Aug 4 15:12:46.837883: NULL [] IKEv1: ESP IKEv2: ESP
Aug 4 15:12:46.837889: CHACHA20_POLY1305 [*256] IKEv1: IKEv2: IKE ESP NSS(AEAD) chacha20poly1305
Aug 4 15:12:46.837892: Hash algorithms:
Aug 4 15:12:46.837896: MD5 IKEv1: IKE IKEv2: NSS
Aug 4 15:12:46.837901: SHA1 IKEv1: IKE IKEv2: IKE FIPS NSS sha
Aug 4 15:12:46.837906: SHA2_256 IKEv1: IKE IKEv2: IKE FIPS NSS sha2, sha256
Aug 4 15:12:46.837910: SHA2_384 IKEv1: IKE IKEv2: IKE FIPS NSS sha384
Aug 4 15:12:46.837915: SHA2_512 IKEv1: IKE IKEv2: IKE FIPS NSS sha512
Aug 4 15:12:46.837919: IDENTITY IKEv1: IKEv2: FIPS
Aug 4 15:12:46.837922: PRF algorithms:
Aug 4 15:12:46.837927: HMAC_MD5 IKEv1: IKE IKEv2: IKE native(HMAC) md5
Aug 4 15:12:46.837931: HMAC_SHA1 IKEv1: IKE IKEv2: IKE FIPS NSS sha, sha1
Aug 4 15:12:46.837936: HMAC_SHA2_256 IKEv1: IKE IKEv2: IKE FIPS NSS sha2, sha256, sha2_256
Aug 4 15:12:46.837950: HMAC_SHA2_384 IKEv1: IKE IKEv2: IKE FIPS NSS sha384, sha2_384
Aug 4 15:12:46.837955: HMAC_SHA2_512 IKEv1: IKE IKEv2: IKE FIPS NSS sha512, sha2_512
Aug 4 15:12:46.837959: AES_XCBC IKEv1: IKEv2: IKE native(XCBC) aes128_xcbc
Aug 4 15:12:46.837962: Integrity algorithms:
Aug 4 15:12:46.837966: HMAC_MD5_96 IKEv1: IKE ESP AH IKEv2: IKE ESP AH native(HMAC) md5, hmac_md5
Aug 4 15:12:46.837984: HMAC_SHA1_96 IKEv1: IKE ESP AH IKEv2: IKE ESP AH FIPS NSS sha, sha1, sha1_96, hmac_sha1
Aug 4 15:12:46.837995: HMAC_SHA2_512_256 IKEv1: IKE ESP AH IKEv2: IKE ESP AH FIPS NSS sha512, sha2_512, sha2_512_256, hmac_sha2_512
Aug 4 15:12:46.837999: HMAC_SHA2_384_192 IKEv1: IKE ESP AH IKEv2: IKE ESP AH FIPS NSS sha384, sha2_384, sha2_384_192, hmac_sha2_384
Aug 4 15:12:46.838005: HMAC_SHA2_256_128 IKEv1: IKE ESP AH IKEv2: IKE ESP AH FIPS NSS sha2, sha256, sha2_256, sha2_256_128, hmac_sha2_256
Aug 4 15:12:46.838008: HMAC_SHA2_256_TRUNCBUG IKEv1: ESP AH IKEv2: AH
Aug 4 15:12:46.838014: AES_XCBC_96 IKEv1: ESP AH IKEv2: IKE ESP AH native(XCBC) aes_xcbc, aes128_xcbc, aes128_xcbc_96
Aug 4 15:12:46.838018: AES_CMAC_96 IKEv1: ESP AH IKEv2: ESP AH FIPS aes_cmac
Aug 4 15:12:46.838023: NONE IKEv1: ESP IKEv2: IKE ESP FIPS null
Aug 4 15:12:46.838026: DH algorithms:
Aug 4 15:12:46.838031: NONE IKEv1: IKEv2: IKE ESP AH FIPS NSS(MODP) null, dh0
Aug 4 15:12:46.838035: MODP1536 IKEv1: IKE ESP AH IKEv2: IKE ESP AH NSS(MODP) dh5
Aug 4 15:12:46.838039: MODP2048 IKEv1: IKE ESP AH IKEv2: IKE ESP AH FIPS NSS(MODP) dh14
Aug 4 15:12:46.838044: MODP3072 IKEv1: IKE ESP AH IKEv2: IKE ESP AH FIPS NSS(MODP) dh15
Aug 4 15:12:46.838048: MODP4096 IKEv1: IKE ESP AH IKEv2: IKE ESP AH FIPS NSS(MODP) dh16
Aug 4 15:12:46.838053: MODP6144 IKEv1: IKE ESP AH IKEv2: IKE ESP AH FIPS NSS(MODP) dh17
Aug 4 15:12:46.838057: MODP8192 IKEv1: IKE ESP AH IKEv2: IKE ESP AH FIPS NSS(MODP) dh18
Aug 4 15:12:46.838061: DH19 IKEv1: IKE IKEv2: IKE ESP AH FIPS NSS(ECP) ecp_256, ecp256
Aug 4 15:12:46.838066: DH20 IKEv1: IKE IKEv2: IKE ESP AH FIPS NSS(ECP) ecp_384, ecp384
Aug 4 15:12:46.838070: DH21 IKEv1: IKE IKEv2: IKE ESP AH FIPS NSS(ECP) ecp_521, ecp521
Aug 4 15:12:46.838074: DH31 IKEv1: IKE IKEv2: IKE ESP AH NSS(ECP) curve25519
Aug 4 15:12:46.838077: IPCOMP algorithms:
Aug 4 15:12:46.838081: DEFLATE IKEv1: ESP AH IKEv2: ESP AH FIPS
Aug 4 15:12:46.838085: LZS IKEv1: IKEv2: ESP AH FIPS
Aug 4 15:12:46.838089: LZJH IKEv1: IKEv2: ESP AH FIPS
Aug 4 15:12:46.838093: testing CAMELLIA_CBC:
Aug 4 15:12:46.838096: Camellia: 16 bytes with 128-bit key
Aug 4 15:12:46.838162: Camellia: 16 bytes with 128-bit key
Aug 4 15:12:46.838201: Camellia: 16 bytes with 256-bit key
Aug 4 15:12:46.838243: Camellia: 16 bytes with 256-bit key
Aug 4 15:12:46.838280: testing AES_GCM_16:
Aug 4 15:12:46.838284: empty string
Aug 4 15:12:46.838319: one block
Aug 4 15:12:46.838352: two blocks
Aug 4 15:12:46.838385: two blocks with associated data
Aug 4 15:12:46.838424: testing AES_CTR:
Aug 4 15:12:46.838428: Encrypting 16 octets using AES-CTR with 128-bit key
Aug 4 15:12:46.838464: Encrypting 32 octets using AES-CTR with 128-bit key
Aug 4 15:12:46.838502: Encrypting 36 octets using AES-CTR with 128-bit key
Aug 4 15:12:46.838541: Encrypting 16 octets using AES-CTR with 192-bit key
Aug 4 15:12:46.838576: Encrypting 32 octets using AES-CTR with 192-bit key
Aug 4 15:12:46.838613: Encrypting 36 octets using AES-CTR with 192-bit key
Aug 4 15:12:46.838651: Encrypting 16 octets using AES-CTR with 256-bit key
Aug 4 15:12:46.838687: Encrypting 32 octets using AES-CTR with 256-bit key
Aug 4 15:12:46.838724: Encrypting 36 octets using AES-CTR with 256-bit key
Aug 4 15:12:46.838763: testing AES_CBC:
Aug 4 15:12:46.838766: Encrypting 16 bytes (1 block) using AES-CBC with 128-bit key
Aug 4 15:12:46.838801: Encrypting 32 bytes (2 blocks) using AES-CBC with 128-bit key
Aug 4 15:12:46.838841: Encrypting 48 bytes (3 blocks) using AES-CBC with 128-bit key
Aug 4 15:12:46.838881: Encrypting 64 bytes (4 blocks) using AES-CBC with 128-bit key
Aug 4 15:12:46.838928: testing AES_XCBC:
Aug 4 15:12:46.838932: RFC 3566 Test Case 1: AES-XCBC-MAC-96 with 0-byte input
Aug 4 15:12:46.839126: RFC 3566 Test Case 2: AES-XCBC-MAC-96 with 3-byte input
Aug 4 15:12:46.839291: RFC 3566 Test Case 3: AES-XCBC-MAC-96 with 16-byte input
Aug 4 15:12:46.839444: RFC 3566 Test Case 4: AES-XCBC-MAC-96 with 20-byte input
Aug 4 15:12:46.839600: RFC 3566 Test Case 5: AES-XCBC-MAC-96 with 32-byte input
Aug 4 15:12:46.839756: RFC 3566 Test Case 6: AES-XCBC-MAC-96 with 34-byte input
Aug 4 15:12:46.839937: RFC 3566 Test Case 7: AES-XCBC-MAC-96 with 1000-byte input
Aug 4 15:12:46.840373: RFC 4434 Test Case AES-XCBC-PRF-128 with 20-byte input (key length 16)
Aug 4 15:12:46.840529: RFC 4434 Test Case AES-XCBC-PRF-128 with 20-byte input (key length 10)
Aug 4 15:12:46.840698: RFC 4434 Test Case AES-XCBC-PRF-128 with 20-byte input (key length 18)
Aug 4 15:12:46.840990: testing HMAC_MD5:
Aug 4 15:12:46.840997: RFC 2104: MD5_HMAC test 1
Aug 4 15:12:46.841200: RFC 2104: MD5_HMAC test 2
Aug 4 15:12:46.841390: RFC 2104: MD5_HMAC test 3
Aug 4 15:12:46.841582: testing HMAC_SHA1:
Aug 4 15:12:46.841585: CAVP: IKEv2 key derivation with HMAC-SHA1
Aug 4 15:12:46.842055: 8 CPU cores online
Aug 4 15:12:46.842062: starting up 7 helper threads
Aug 4 15:12:46.842128: started thread for helper 0
Aug 4 15:12:46.842174: helper(1) seccomp security disabled for crypto helper 1
Aug 4 15:12:46.842188: started thread for helper 1
Aug 4 15:12:46.842219: helper(2) seccomp security disabled for crypto helper 2
Aug 4 15:12:46.842236: started thread for helper 2
Aug 4 15:12:46.842258: helper(3) seccomp security disabled for crypto helper 3
Aug 4 15:12:46.842269: started thread for helper 3
Aug 4 15:12:46.842296: helper(4) seccomp security disabled for crypto helper 4
Aug 4 15:12:46.842311: started thread for helper 4
Aug 4 15:12:46.842323: helper(5) seccomp security disabled for crypto helper 5
Aug 4 15:12:46.842346: started thread for helper 5
Aug 4 15:12:46.842369: helper(6) seccomp security disabled for crypto helper 6
Aug 4 15:12:46.842376: started thread for helper 6
Aug 4 15:12:46.842390: using Linux xfrm kernel support code on #1 SMP PREEMPT_DYNAMIC Thu Jul 20 09:11:28 EDT 2023
Aug 4 15:12:46.842393: helper(7) seccomp security disabled for crypto helper 7
Aug 4 15:12:46.842707: selinux support is NOT enabled.
Aug 4 15:12:46.842728: systemd watchdog not enabled - not sending watchdog keepalives
Aug 4 15:12:46.843813: seccomp security disabled
Aug 4 15:12:46.848083: listening for IKE messages
Aug 4 15:12:46.848252: Kernel supports NIC esp-hw-offload
Aug 4 15:12:46.848534: adding UDP interface ovn-k8s-mp0 10.129.0.2:500
Aug 4 15:12:46.848624: adding UDP interface ovn-k8s-mp0 10.129.0.2:4500
Aug 4 15:12:46.848654: adding UDP interface br-ex 169.254.169.2:500
Aug 4 15:12:46.848681: adding UDP interface br-ex 169.254.169.2:4500
Aug 4 15:12:46.848713: adding UDP interface br-ex 10.0.0.8:500
Aug 4 15:12:46.848740: adding UDP interface br-ex 10.0.0.8:4500
Aug 4 15:12:46.848767: adding UDP interface lo 127.0.0.1:500
Aug 4 15:12:46.848793: adding UDP interface lo 127.0.0.1:4500
Aug 4 15:12:46.848824: adding UDP interface lo [::1]:500
Aug 4 15:12:46.848853: adding UDP interface lo [::1]:4500
Aug 4 15:12:46.851160: loading secrets from "/etc/ipsec.secrets"
Aug 4 15:12:46.851214: no secrets filename matched "/etc/ipsec.d/*.secrets"
Aug 4 15:12:47.053369: loading secrets from "/etc/ipsec.secrets"
sh-4.4# tcpdump -i any esp
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked v1), capture size 262144 bytes^C
0 packets capturedsh-5.1# ovn-nbctl --no-leader-only get nb_global . ipsec
false
Version-Release number of selected component (if applicable):
openshift/cluster-network-operator#1874
How reproducible:
Always
Steps to Reproduce:
1.Install OVN cluster and enable IPSec in runtime 2. 3.
Actual results:
no esp packets seen across the nodes
Expected results:
esp traffic should be seen across the nodes
Additional info:
OC mirror is GA product as of Openshift 4.11 .
The goal of this feature is to solve any future customer request for new features or capabilities in OC mirror
Overview
This epic is a simple tracker epic for the proposed work and analysis for 4.14 delivery
As a oc-mirror user, I would like mirrored operator catalogs to have valid caches that reflect the contents of the catalog (configs folder) based on the filtering done in the ImageSetConfig for that catalog
so that the catalog image starts efficiently in a cluster.
Tasks:
- white-out /tmp on all manifests (per platform)
- Recreate the cache under /tmp/cache using
- extract the whole catalog
- use the opm binary included in the extracted catalog to call (command line)
opm serve /configs –-cache-dir /tmp/cache –-cache-only
- Create a new layer from /configs and /tmp/cache
- the /tmp is compatible with all platforms
- oc-mirror should not change the CMD nor ENTRYPOINT of the image
- Rebuild catalog image up to the index (manifest list)
Acceptance criteria:
- Run the catalog container with command opm serve <configDir> --cache-dir=<cacheDir> --cache-only --cache-enforce-integrity to verify the integrity of the cache
- 4.14 catalogs mirrored with oc-mirror v4.14 run correctly in a cluster
- when mirrored with mirrorToMirror workflow
- when mirrored with mirrorToMirror workflow with --include-oci-local-catalogs
- when mirrored with mirrorToDisk + diskToMirror workflow
- 4.14 catalogs mirrored with oc-mirror v4.14 use the pre-computed cache (not sure how to test this)
- catalogs<= 4.13 mirrored with oc-mirror v4.14 run correctly in a cluster (this is not something we publish as supported)
Description of problem:
Customer was able to limit the nested repository path with "oc adm catalog mirror" by using the argument "--max-components" but there is no alternate solution along with "oc-mirror" binary while we are suggesting to use "oc-mirror" binary for mirroring.for example: Mirroring will work if we mirror like below oc mirror --config=./imageset-config.yaml docker://registry.gitlab.com/xxx/yyy Mirroring will fail with 401 unauthorized if we add one more nested path like below oc mirror --config=./imageset-config.yaml docker://registry.gitlab.com/xxx/yyy/zzz
Version-Release number of selected component (if applicable):
How reproducible:
We can reproduce the issue by using a repository which is not supported deep nested paths
Steps to Reproduce:
1. Create a imageset to mirror any operator
kind: ImageSetConfiguration
apiVersion: mirror.openshift.io/v1alpha2
storageConfig:
local:
path: ./oc-mirror-metadata
mirror:
operators:
- catalog: registry.redhat.io/redhat/redhat-operator-index:v4.12
packages:
- name: local-storage-operator
channels:
- name: stable
2. Do the mirroring to a registry where its not supported deep nested repository path, Here its gitlab and its doesnt not support netsting beyond 3 levels deep.
oc mirror --config=./imageset-config.yaml docker://registry.gitlab.com/xxx/yyy/zzz
this mirroring will fail with 401 unauthorized error
3. if try to mirror the same imageset by removing one path it will work without any issues, like below
oc mirror --config=./imageset-config.yaml docker://registry.gitlab.com/xxx/yyy
Actual results:
Expected results:
Need a alternative option of "--max-components" to limit the nested path in "oc-mirror"
Additional info:
Proposed title of this feature request
Achieve feature parity for recently introduced functionality for all modes of operation
Nature and description of the request
Currently there are gaps in functionality within oc mirror that we would like addressed.
1. Support oci: references within mirror.operators[].catalog in an ImageSetConfiguration when running in all modes of operation with the full functionality provided by oc mirror.
Currently oci: references such as the following are allowed only in limited circumstances:
mirror: operators: - catalog: oci:///tmp/oci/ocp11840 - catalog: icr.io/cpopen/ibm-operator-catalog
Currently supported scenarios
- Mirror to Mirror
In this mode of operation the images are fetched from the oci: reference rather than being pulled from a source docker image repository. These catalogs are processed through similar (yet different) mechanisms compared to docker image references. The end result in this scenario is that the catalog is potentially modified and images (i.e. catalog, bundle, related images, etc.) are pushed to their final docker image repository. This provides the full capabilities offered by oc mirror (e.g. catalog "filtering", image pruning, metadata manipulation to keep track of what has been mirrored, etc.)
Desired scenarios
In the following scenarios we would like oci: references to be processed in a similar way to how docker references are handled (as close as possible anyway given the different APIs involved). Ultimately we want oci: catalog references to provide the full set of functionality currently available for catalogs provided as a docker image reference. In other words we want full feature parity (e.g. catalog "filtering", image pruning, metadata manipulation to keep track of what has been mirrored, etc.)
- Mirror to Disk
In this mode of operation the images are fetched from the oci: reference rather than being pulled from a docker image repository. These catalogs are processed through similar yet different mechanisms compared to docker image references. The end result of this scenario is that all mappings and catalogs are packaged into tar archives (i.e. the "imageset").
- Disk to Mirror
In this mode of operation the tar archives (i.e. the "imageset") are processed via the "publish mechanism" which means unpacking the tar archives, processing the metadata, pruning images, rebuilding catalogs, and pushing images to their destination. In theory if the mirror-to-disk scenario is handled properly, then this mode should "just work".
Below the line was the original RFE for requesting the OCI feature and is only provided for reference.
Overview
Design , code and implementation of the mirrorToDisk functionality
... so that I can use that along with the OCI FBC feature
Goal:
As a cluster administrator, I want OpenShift to include a recent HAProxy version, so that I have the latest available performance and security fixes.
Description:
We should strive to follow upstream HAProxy releases by bumping the HAProxy version that we ship in OpenShift with every 4.y release, so that OpenShift benefits from upstream performance and security fixes, and so that we avoid large version-number jumps when an urgent fix necessitates bumping to the latest HAProxy release. This bump should happen as early as possible in the OpenShift release cycle, so as to maximize soak time.
For OpenShift 4.13, this means bumping to 2.6.
As a cluster administrator,
I want OpenShift to include a recent HAProxy version,
so that I have the latest available performance and security fixes.
We should strive to follow upstream HAProxy releases by bumping the HAProxy version that we ship in OpenShift with every 4.y release, so that OpenShift benefits from upstream performance and security fixes, and so that we avoid large version-number jumps when an urgent fix necessitates bumping to the latest HAProxy release. This bump should happen as early as possible in the OpenShift release cycle, so as to maximize soak time.
For OpenShift 4.14, this means bumping to 2.6.
Bump the HAProxy version in dist-git so that OCP 4.13 ships HAProxy 2.6.13, with this patch added on top: https://git.haproxy.org/?p=haproxy-2.6.git;a=commit;h=2b0aafdc92f691bc4b987300c9001a7cc3fb8d08. The patch fixes the segfault that was being tracked as OCPBUGS-13232.
This patch is in HAProxy 2.6.14, so we can stop carrying the patch once we bump to HAProxy 2.6.14 or newer in a subsequent OCP release.
Feature Overview (aka. Goal Summary)
Tang-enforced, network-bound disk encryption has been available in OpenShift for some time, but all intended Tang-endpoints contributing unique key material to the process must be reachable during RHEL CoreOS provisioning in order to complete deployment.
If a user wants to require 3 of 6 tang servers be reachable than all 6 must be reachable during the provisioning process. This might not be possible due to maintenance, outage, or simply network policy during deployment.
Enabling offline provisioning for first boot will help all of these scenarios.
Goals (aka. expected user outcomes)
The user can now provision a cluster with some or none of the Tang servers being reachable on first boot. Second boot, of course, will be subject to the Tang requirements being configured.
Done when:
- Ignition spec default has been updated to 3.4
- reconcile field (dependent on ignition 3.4)
- consider Tang rotation? (write another epic)
This requires messy/complex work of grepping through for prior references to ignition and updating golang types that reference other versions.
Assumption that existing tests are sufficient to catch discrepancies.
Goal
Allow to point to an existing OVA image stored in vSphere from the OpenShift installer, replacing the current method that uploads the OVA template every time an OpenShift cluster is installed.
Why is this important?
This is an improvement that makes the installation more efficient by not having to upload an OVA from where openshift-install is running every time a cluster is installed, saving time and bandwidth use. For example if an administrating is installing from a VPN then the OVA is upload through it to the target cluster every time an OpenShift cluster is installed. This makes the administration process more efficient by having a OVA centralised ready to use to install new clusters without uploading it from where the installer is run.
Epic Goal
- To allow the use of a pre-existing RHCOS virtual machine or template via the IPI installer.
Why is this important?
- It is a very common workflow in vSphere to upload a OVA. In the disconnected scenario the requirement of using a local web server, copying an ova to that webserver and then running the installer is a poor experience.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Feature Goal
- Enable platform=external to support onboarding new partners, e.g. Oracle Cloud Infrastructure and VCSP partners.
- Create a new platform type, working name "External", that will signify when a cluster is deployed on a partner infrastructure where core cluster components have been replaced by the partner. “External” is different from our current platform types in that it will signal that the infrastructure is specifically not “None” or any of the known providers (eg AWS, GCP, etc). This will allow infrastructure partners to clearly designate when their OpenShift deployments contain components that replace the core Red Hat components.
This work will require updates to the core OpenShift API repository to add the new platform type, and then a distribution of this change to all components that use the platform type information. For components that partners might replace, per-component action will need to be taken, with the project team's guidance, to ensure that the component properly handles the "External" platform. These changes will look slightly different for each component.
To integrate these changes more easily into OpenShift, it is possible to take a multi-phase approach which could be spread over a release boundary (eg phase 1 is done in 4.X, phase 2 is done in 4.X+1).
OCPBU-5: Phase 1
- Write platform “External” enhancement.
- Evaluate changes to cluster capability annotations to ensure coverage for all replaceable components.
- Meet with component teams to plan specific changes that will allow for supplement or replacement under platform "External".
- Start implementing changes towards Phase 2.
OCPBU-510: Phase 2
- Update OpenShift API with new platform and ensure all components have updated dependencies.
- Update capabilities API to include coverage for all replaceable components.
- Ensure all Red Hat operators tolerate the "External" platform and treat it the same as "None" platform.
OCPBU-329: Phase.Next
- TBD
Why is this important?
- As partners begin to supplement OpenShift's core functionality with their own platform specific components, having a way to recognize clusters that are in this state helps Red Hat created components to know when they should expect their functionality to be replaced or supplemented. Adding a new platform type is a significant data point that will allow Red Hat components to understand the cluster configuration and make any specific adjustments to their operation while a partner's component may be performing a similar duty.
- The new platform type also helps with support to give a clear signal that a cluster has modifications to its core components that might require additional interaction with the partner instead of Red Hat. When combined with the cluster capabilities configuration, the platform "External" can be used to positively identify when a cluster is being supplemented by a partner, and which components are being supplemented or replaced.
Scenarios
- A partner wishes to replace the Machine controller with a custom version that they have written for their infrastructure. Setting the platform to "External" and advertising the Machine API capability gives a clear signal to the Red Hat created Machine API components that they should start the infrastructure generic controllers but not start a Machine controller.
- A partner wishes to add their own Cloud Controller Manager (CCM) written for their infrastructure. Setting the platform to "External" and advertising the CCM capability gives a clear to the Red Hat created CCM operator that the cluster should be configured for an external CCM that will be managed outside the operator. Although the Red Hat operator will not provide this functionality, it will configure the cluster to expect a CCM.
Acceptance Criteria
Phase 1
- Partners can read "External" platform enhancement and plan for their platform integrations.
- Teams can view jira cards for component changes and capability updates and plan their work as appropriate.
Phase 2
- Components running in cluster can detect the “External” platform through the Infrastructure config API
- Components running in cluster react to “External” platform as if it is “None” platform
- Partners can disable any of the platform specific components through the capabilities API
Phase 3
- Components running in cluster react to the “External” platform based on their function.
- for example, the Machine API Operator needs to run a set of controllers that are platform agnostic when running in platform “External” mode.
- the specific component reactions are difficult to predict currently, this criteria could change based on the output of phase 1.
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- Phase 1 requires talking with several component teams, the specific action that will be needed will depend on the needs of the specific component. At the least the components need to treat platform "External" as "None", but there could be more changes depending on the component (eg Machine API Operator running non-platform specific controllers).
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Empower External platform type user to specify when they will run their own CCM
Why is this important?
- For partners wishing to use components that require zonal awareness provided by the infrastructure (for example CSI drivers), they will need to exercise their own cloud controller managers. This epic is about adding the proper configuration to OpenShift to allow users of External platform types to run their own CCMs.
Scenarios
- As a Red Hat partner, I would like to deploy OpenShift with my own CSI driver. To do this I need my CCM deployed as well. Having a way to instruct OpenShift to expect an external CCM deployment would allow me to do this.
Acceptance Criteria
- CI - A new periodic test based on the External platform test would be ideal
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Update docs.ci.openshift.org with CCM docs
Dependencies (internal and external)
- ...
Previous Work (Optional):
- https://github.com/openshift/enhancements/blob/master/enhancements/cloud-integration/infrastructure-external-platform-type.md#api-extensions
- https://github.com/openshift/api/pull/1409
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story
As a Red Hat Partner installing OpenShift using the External platform type, I would like to install my own Cloud Controller Manager(CCM). Having a field in the Infrastructure configuration object to signal that I will install my own CCM and that Kubernetes should be configured to expect an external CCM will allow me to run my own CCM on new OpenShift deployments.
Background
This work has been defined in the External platform enhancement , and had previously been part of openshift/api . The CCM API pieces were removed for the 4.13 release of OpenShift to ensure that we did not ship unused portions of the API.
In addition to the API changes, library-go will need to have an update to the IsCloudProviderExternal function to detect the if the External platform is selected and if the CCM should be enabled for external mode.
We will also need to check the ObserveCloudVolumePlugin function to ensure that it is not affected by the external changes and that it continues to use the external volume plugin.
After updating openshift/library-go, it will need to be re-vendored into the MCO , KCMO , and CCCMO (although this is not as critical as the other 2).
Steps
- update openshift/api with new CCM fields (re-revert #1409)
- revendor api to library-go
- update IsCloudProviderExternal in library-go to observe the new API fields
- investigate ObserveCloudVolumePlugin to see if it requires changes
- revendor library-go to MCO, KCMO, and CCCMO
- update enhancement doc to reflect state
Stakeholders
- openshift eng
- oracle cloud install effort
Definition of Done
- openshift can be installed with External platform type with kubelet, and related components, using the external cloud provider flags.
- Docs
- this will need to be documented in the API and as part of
OCPCLOUD-1581
- Testing
- this will need validation through unit test, integration testing may be difficult as we will need a new e2e built off the external platform with a ccm
- https://github.com/openshift/cluster-cloud-controller-manager-operator/pull/253
- https://github.com/openshift/cluster-config-operator/pull/331
- https://github.com/openshift/cluster-config-operator/pull/306
- https://github.com/openshift/cluster-kube-controller-manager-operator/pull/736
- https://github.com/openshift/machine-config-operator/pull/3745
User Story
As a user I want to use the openshift installer to create clusters of platform type External so that I can use openshift more effectively on a partner provider platform.
Background
To fully support the External platform type for partners and users, it will be useful to be able to have the installer understand when it sees the external platform type in the install-config.yaml, and then to properly populate the resulting infrastructure config object with the external platform type and platform name.
As defined in https://github.com/openshift/api/blob/master/config/v1/types_infrastructure.go#L241 , the external platform type allows the user to specify a name for the platform. This card is about updating the installer so that a user can provide both the external type and a platform name that will be expressed in the infrastructure manifest.
Aside from this information, the installer should continue with a normal platform "None" installation.
Steps
- update installer to allow platform "External" specified in the install-config.yaml
- update installer to allow platform name to specified as part of the External platform configuration
Stakeholders
- openshift cloud infra team
- openshift installer team
- openshift assisted installer team
Definition of Done
- user can specify external platform in the install-config.yaml and have a cluster with External platform type and a name for the platform.
- cluster installs as expected for platform external (similar to none)
- Docs
- the initial documentation for this will be contained in the developer generated docs defined by https://issues.redhat.com/browse/OCPCLOUD-1581
- Testing
- this feature should allow us to update our external platform tests to make the installation easier, tests should be updated to include this methodology
Feature Overview
In the initial delivery of CoreOS Layering, it is required that administrators provide their own build environment to customize RHCOS images. That could be a traditional RHEL environment or potentially an enterprising administrator with some knowledge of OCP Builds could set theirs up on-cluster.
The primary virtue of an on-cluster build path is to continue using the cluster to manage the cluster. No external dependency, batteries-included.
MVP: bring the off-cluster build environment on-cluster
-
- Repo control
- rpm-ostree needs repo management commands
- Entitlement management
- Repo control
In the context of the Machine Config Operator (MCO) in Red Hat OpenShift, on-cluster builds refer to the process of building an OS image directly on the OpenShift cluster, rather than building them outside the cluster (such as on a local machine or continuous integration (CI) pipeline) and then making a configuration change so that the cluster uses them. By doing this, we enable cluster administrators to have more control over the contents and configuration of their clusters’ OS image through a familiar interface (MachineConfigs and in the future, Dockerfiles).
This is the "consumption" side of the security – rpm-ostree needs to be able to retrieve images from the internal registry seamlessly.
This will involve setting up (or using some existing) pull secrets, and then getting them to the proper location on disk so that rpm-ostree can use them to pull images.
At the layering sync meeting on Thursday, August 10th, it was decided that for this to be considered ready for Dev / Tech Preview, cluster admins need a way to inject custom Dockerfiles into their on-cluster builds.
(Commentary: It was also decided 4 months ago that this was not an MVP requirement in https://docs.google.com/document/d/1QSsq0mCgOSUoKZ2TpCWjzrQpKfMUL9thUFBMaPxYSLY/edit#heading=h.jqagm7kwv0lg. And quite frankly, this requirement should have been known at that point in time as opposed to the week before tech preview.)
The first phase of the layering effort involved creating a BuildController, whose job is to start and manage builds using the OpenShift Build API. We can use the work done to create the BuildController as the basis for our MVP. However, what we need from BuildController right now is less than BuildController currently provides. With that in mind, we need to remove certain parts of BuildController to create a more streamlined and simpler implementation ideal for an MVP.
Done when a version of BuildController is landed which does the following things:
- Listens for all MachineConfigPool events. If a MachineConfigPool with a specific label or annotation (e.g., machineconfiguration.openshift.io/layering-enabled), the BuildController should retrieve the latest rendered MachineConfig associated with the MachineConfigPool, generate a series of inputs to a builder backend (for now, the OpenShift Build API can be the first backend), then update the MachineConfigPool with the outcome of that action. In the case of a successful build, the MachineConfigPool should be updated with the image pullspec for the newly-built image. For now, this can come in the form of an annotation or a label (e.g., machineconfiguration.openshift.io/desired-os-image = "image-registry.openshift-image-registry.svc:5000/openshift-machine-config-operator/coreos@sha256:abcdef1234567890...). But eventually, it should be a Status field on the MachineConfigPool object.
- Reads from a ConfigMap which contains the following items (let's call it machine-os-builder-config for now):
- Name of the base OS image pull secret.
- Name of the final OS image push secret.
- Target container registry and org / repo information for where to push the final OS image (e.g., image-registry.openshift-image-registry.svc:5000/openshift-machine-config-operator/coreos).
- All functionality around managing ImageStreams and OpenShift Builds is removed or decoupled. In the case of the OpenShift Build functionality, it will be decoupled instead of completely removed. Additionally, it should not use BuildConfigs. It should instead create and manage image Build objects directly.
- Use contexts for handling shutdowns and timeouts.
- Unit tests are written for the major BuildController functionalities using either FakeClient or EnvTest.
- The modified BuildController and its tests are merged into the master branch of the MCO. Note: This does not mean that it will be immediately active in the MCO's execution path. However, tests will be executed in CI.
The second phase of the layering effort involved creating a BuildController, whose job is to start and manage builds of OS images. While it should be able to perform those functions on its own, getting the built OS image onto each of the cluster nodes involves modifying other parts of the MCO to be layering-aware. To that end, there are three pieces involve, some of which will require modification:
Render Controller
Right now, the render controller listens for incoming MachineConfig changes. It generates the rendered config which is comprised of all of the MachineConfigs for a given MachineConfigPool. Once rendered, the Render Controller updates the MachineConfigPool to point to the new config. This portion of the MCO will not likely need any modification that I'm aware of at the moment.
Node Controller
The Node Controller listens for MachineConfigPool config changes. Whenever it identifies that a change has occurred, it applies the machineconfiguration.openshift.io/desiredConfig annotation to all the nodes in the targeted MachineConfigPool which causes the Machine Config Daemon (MCD) to apply the new configs. With this new layering mechanism, we'll need to add the additional annotation of machineconfiguration.openshift.io/desiredOSimage which will contain the fully-qualified pullspec for the new OS image (referenced by the image SHA256 sum). To be clear, we will not be replacing the desiredConfig annotation with the desiredOSimage annotation; both will still be used. This will allow Config Drift Monitor to continue to function the way it does with no modification required.
Machine Config Daemon
Right now, the MCD listens to Node objects for changes to the machineconfiguration.openshift.io/desiredConfig annotation. With the new desiredOSimage annotation being present, the MCD will need to skip the parts of the update loop which write files and systemd units to disk. Instead, it will skip directly to the rpm-ostree application phase (after making sure the correct pull secrets are in place, etc.).
Done When:
- The above modifications are made.
- Each modification has been done with appropriate unit tests where feasible.
To speed development for on-cluster builds and avoid a lot of complex code paths, the decision was made to put all functionality related to building OS images and managing internal registries into a separate binary within the MCO.
Eventually, this binary will be responsible for running the productionized BuildController and know how to respond to Machine OS Builder API objects. However, until the productionized BuildController and opt-in portions are ready, the first pass of this binary will be much simpler: For now, it can connect to the API server and print a "Hello World".
Done When:
- We have a new binary under cmd/machine-os-builder. This binary will be built alongside the current MCO components and will be baked into the MCO image.
- The Dockerfile, Makefile, and build scripts will need some modification so that they how to build cmd/machine-os-builder.
- A Deployment manifest is created under manifests/ which is set up to start up a single instance of the new binary though we don't want it to start up by default right now since it won't do anything useful.
Feature Overview
- Support OpenShift to be deployed on AWS Local Zones
Goals
- Support OpenShift to be deployed from day-0 on AWS Local Zones
- Support an existing OpenShift cluster to deploy compute Nodes on AWS Local Zones (day-2)
AWS Local Zones support - feature delivered in phases:
- Phase 0 (
OCPPLAN-9630): Document how to create compute nodes on AWS Local Zones in day-0 (SPLAT-635) - Phase 1 (
OCPBU-2): Create edge compute pool to generate MachineSets for node with NoSchedule taints when installing a cluster in existing VPC with AWS Local Zone subnets (SPLAT-636) - Phase 2 (
OCPBU-351): Installer automates network resources creation on Local Zone based on the edge compute pool (SPLAT-657)
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Epic Goal
Fully automated installation creating subnets in AWS Local Zones when the zone names are added to the edge compute pool on install-config.yaml.
- The installer should create the subnets on the Local Zones according to the configuration of the "edge" compute pool, provided on install-config.yaml
Why is this important?
- Users can extend the presence of worker nodes closer to the metropolitan regions, where the users or on-premises workloads are running, decreasing the time to deliver their workloads to their clients.
Scenarios
- As a cluster admin, I would like to install OpenShift clusters, extending the compute nodes to the Local Zones in my day-zero operations without needing to set up the network and compute dependencies, so I can speed up the edge adoption in my organization using OCP.
Acceptance Criteria
- CI - MUST be running successfully with tests automated.
- CI - custom jobs should be added to test Local Zone provisioning
- Release Technical Enablement - Provide necessary release enablement details and documents.
- The PR on the installer repo should be merged after being approved by the Installer team, QE, and docs

- The product documentation has been created
Dependencies (internal and external)
SPLAT-636: install a cluster in existing VPC extending workers to Local ZonesOCPBUGSM-46513: Bug - Ingress Controller should not add Local Zones subnets to network routers/LBs (Classic/NLB)
Previous Work (Optional):
- Enhancement 1232
SPLAT-636: AWS Local Zones - Phase 1 IPI edge pool - Installer support to automatically create the MachineSets when installing in existing VPC
Open questions:
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Local Zones BYON: https://github.com/openshift/release/pull/39902
- Local Zones Full IPI: https://github.com/openshift/release/pull/40031
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Enhancement Proposal merged: https://github.com/openshift/enhancements/pull/1232
- DEV - Upstream code and tests merged: https://github.com/openshift/installer/pull/7137
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: https://polarion.engineering.redhat.com/polarion/#/project/OSE/workitems?query=trello%3ASPLAT%5C-657
- QE - Automated tests merged: https://github.com/openshift/release/pull/41574
- DOC - Downstream documentation merged: https://github.com/openshift/openshift-docs/pull/60771
Feature Overview
- As a Cluster Administrator, I want to opt-out of certain operators at deployment time using any of the supported installation methods (UPI, IPI, Assisted Installer, Agent-based Installer) from UI (e.g. OCP Console, OCM, Assisted Installer), CLI (e.g. oc, rosa), and API.
- As a Cluster Administrator, I want to opt-in to previously-disabled operators (at deployment time) from UI (e.g. OCP Console, OCM, Assisted Installer), CLI (e.g. oc, rosa), and API.
- As a ROSA service administrator, I want to exclude/disable Cluster Monitoring when I deploy OpenShift with HyperShift — using any of the supported installation methods including the ROSA wizard in OCM and rosa cli — since I get cluster metrics from the control plane. This configuration should be persisted through not only through initial deployment but also through cluster lifecycle operations like upgrades.
- As a ROSA service administrator, I want to exclude/disable Ingress Operator when I deploy OpenShift with HyperShift — using any of the supported installation methods including the ROSA wizard in OCM and rosa cli — as I want to use my preferred load balancer (i.e. AWS load balancer). This configuration should be persisted through not only through initial deployment but also through cluster lifecycle operations like upgrades.
Goals
- Make it possible for customers and Red Hat teams producing OCP distributions/topologies/experiences to enable/disable some CVO components while still keeping their cluster supported.
Scenarios
- This feature must consider the different deployment footprints including self-managed and managed OpenShift, connected vs. disconnected (restricted and air-gapped), supported topologies (standard HA, compact cluster, SNO), etc.
- Enabled/disabled configuration must persist throughout cluster lifecycle including upgrades.
- If there's any risk/impact of data loss or service unavailability (for Day 2 operations), the System must provide guidance on what the risks are and let user decide if risk worth undertaking.
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This part of the overall multiple release Composable OpenShift (OCPPLAN-9638 effort), which is being delivered in multiple phases:
Phase 1 (OpenShift 4.11): OCPPLAN-7589 Provide a way with CVO to allow disabling and enabling of operators
CORS-1873Installer to allow users to select OpenShift components to be included/excludedOTA-555Provide a way with CVO to allow disabling and enabling of operatorsOLM-2415Make the marketplace operator optionalSO-11Make samples operator optionalMETAL-162Make cluster baremetal operator optionalOCPPLAN-8286CI Job for disabled optional capabilities
Phase 2 (OpenShift 4.12): OCPPLAN-7589 Provide a way with CVO to allow disabling and enabling of operators
CONSOLE-3160Make console operator optionalCCXDEV-8079Make Insights operator optionalCNF-5645Make storage operator optionalCNF-5646Make csi-snapshot-controller optional
Phase 3 (OpenShift 4.13): OCPBU-117
OTA-554Make oc aware of cluster capabilitiesPSAP-741Make Node Tuning Operator (including PAO controllers) optional
Phase 4 (OpenShift 4.14): OCPSTRAT-36 (formerly OCPBU-236)
CCO-186ccoctl support for credentialing optional capabilitiesMCO-499MCD should manage certificates via a separate, non-MC path (formerlyIR-230Make node-ca managed by CVO)CNF-5642Make cluster autoscaler optionalCNF-5643- Make machine-api operator optionalWRKLDS-695- Make DeploymentConfig API + controller optionalCNV-16274OpenShift Virtualization on the Red Hat Application Cloud (not applicable)CNF-9115- Leverage Composable OpenShift feature to make control-plane-machine-set optional
Phase 5 (OpenShift 4.15): OCPSTRAT-421 (formerly) OCPBU-519
OCPBU-352Make Ingress Operator optionalBUILD-565- Make Build v1 API + controller optional- OBSDA-242 Make Cluster Monitoring Operator optional
OCPVE-630(formerlyCNF-5647) Leverage Composable OpenShift feature to make image-registry optional (replacesIR-351- Make Image Registry Operator optional)CNF-9114- Leverage Composable OpenShift feature to make olm optionalCNF-9118- Leverage Composable OpenShift feature to make cloud-credential optionalCNF-9119- Leverage Composable OpenShift feature to make cloud-controller-manager optional
Phase 6 (OpenShift 4.16): OCPSTRAT-731
- TBD
References
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Per https://github.com/openshift/enhancements/pull/922 we need `oc adm release new` to parse the resource manifests for `capability` annotations and generate a yaml file that lists the valid capability names, to embed in the release image.
This file can be used by the installer to error or warn when the install config lists capabilities for enable/disable that are not valid capability names.
Note: Moved the couple of cards from OTA-554 to this epic as these cards are relatively less priority for 4.13 release and we could not mark these done.
oc adm release extract --included ... or some such, that only works when no release pullspec is given, where oc connects to the cluster to ask after the current release image (as it does today when you leave off a pullspec) but also collects FeatureGates and cluster profile and all that sort of stuff so it can write only the manifests it expects the CVO to be attempting to reconcile.
This would be narrowly useful for ccoctl (see CCO-178 and CCO-186), because with this extract option, ccoctl wouldn't need to try to reproduce "which of these CredentialsRequests manifests does the cluster actually want filled?" locally.
It also seems like it would be useful for anyone trying to get a better feel for what the CVO is up to in their cluster, for the same reason that it reduces distracting manifests that don't apply.
The downside is that if we screw up the inclusion logic, we could have oc diverging from the CVO, and end up increasing confusion instead of decreasing confusion. If we move the inclusion logic to library-go, that reduces the risk a bit, but there's always the possibility that users are using an oc that is older or newer than the cluster's CVO. Some way to have oc warn when the option is used but the version differs from the current CVO version would be useful, but possibly complicated to implement, unless we take shortcuts like assuming that the currently running CVO has a version matched to the ClusterVersion's status.desired target.
Definition of done (more details in the OTA-692 spike comment):
- Add a new --included flag to $ oc adm release extract --to <dir path> <pull-spec or version-number>. The --included flag filters extracted manifests to those that are expected to be included with the cluster.
here is a sketch of code which W. Trevor King suggested
While working on OTA-559, my oc#1237 broke JSON output, and needed a follow-up fix. To avoid destabilizing folks who consume the dev-tip oc, we should grow CI presubmits to exercise critical oc adm release ... pathways, to avoid that kind of accidental breakage.
So it's easier to make adjustments without having to copy/paste code between branches.
Epic Goal
- Add an optional capability that allows disabling the image registry operator entirely
Why is this important?
It is already possibly to run a cluster with no instantiated image registry, but the image registry operator itself always runs. This is an unnecessary use of resources for clusters that don't need/want a registry. Making it possible to disable this will reduce the resource footprint as well as bug risks for clusters that don't need it, such as SNO and OKE.
Acceptance Criteria
- CI - MUST be running successfully with tests automated (we have an existing CI job that runs a cluster with all optional capabilities disabled. Passing that job will require disabling certain image registry tests when the cap is disabled)
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
-
MCO-499must be completed first because we still need the CA management logic running even if the image registry operator is not running.
Previous Work (Optional):
- The optional cap architecture and guidance for adding a new capability is described here: https://github.com/openshift/enhancements/blob/master/enhancements/installer/component-selection.md
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To enable the MCO to replace the node-ca, the registry operator needs to provide its own CAs in isolation.
Currently, the registry provides its own CAs via the "image-registry-certificates" configmap. This configmap is a merge of the service ca, storage ca, and additionalTrustedCA (from images.config.openshift.io/cluster).
Because the MCO already has access to additionalTrustedCA, the new secret does not need to contain it.
ACCEPTANCE CRITERIA
TBD
- Proposed title of this feature request:
Update ETCD datastore encryption to use AES-GCM instead of AES-CBC
2. What is the nature and description of the request?
The current ETCD datastore encryption solution uses the aes-cbc cipher. This cipher is now considered "weak" and is susceptible to padding oracle attack. Upstream recommends using the AES-GCM cipher. AES-GCM will require automation to rotate secrets for every 200k writes.
The cipher used is hard coded.
3. Why is this needed? (List the business requirements here).
Security conscious customers will not accept the presence and use of weak ciphers in an OpenShift cluster. Continuing to use the AES-CBC cipher will create friction in sales and, for existing customers, may result in OpenShift being blocked from being deployed in production.
4. List any affected packages or components.
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
The Kube APIserver is used to set the encryption of data stored in etcd. See https://docs.openshift.com/container-platform/4.11/security/encrypting-etcd.html
Today with OpenShift 4.11 or earlier, only aescbc is allowed as the encryption field type.
RFE-3095 is asking that aesgcm (which is an updated and more recent type) be supported. Furthermore RFE-3338 is asking for more customizability which brings us to how we have implemented cipher customzation with tlsSecurityProfile. See https://docs.openshift.com/container-platform/4.11/security/tls-security-profiles.html
Why is this important? (mandatory)
AES-CBC is considered as a weak cipher
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
The new aesgcm encryption provider was added in 4.13 as techpreview, but as part of https://issues.redhat.com/browse/API-1509, the feature needs to be GA in OCP 4.13.
AES-GCM encryption was enabled in cluster-openshift-apiserver-operator and cluster-openshift-autenthication-operator, but not in the cluster-kube-apiserver-operator. When trying to enable aesgcm encryption in the apiserver config, the kas-operator will produce an error saying that the aesgcm provider is not supported.
The new aesgcm encryption provider was added in 4.13 as techpreview, but as part of https://issues.redhat.com/browse/API-1509, the feature needs to be GA in OCP 4.13.
The new aesgcm encryption provider was added in 4.13 as techpreview, but as part of https://issues.redhat.com/browse/API-1509, the feature needs to be GA in OCP 4.13.
The new aesgcm encryption provider was added in 4.13 as techpreview, but as part of https://issues.redhat.com/browse/API-1509, the feature needs to be GA in OCP 4.13.
Feature Overview
Support Platform external to allow installing with agent on OCI, with focus on https://www.oracle.com/cloud/cloud-at-customer/dedicated-region/faq/ for disconnected, on-prem.
Related / parent feature
OCPSTRAT-510 OpenShift on Oracle Cloud Infrastructure (OCI) with VMs
Feature Overview
Support Platform external to allow installing with agent on OCI, with focus on https://www.oracle.com/cloud/cloud-at-customer/dedicated-region/faq/ for disconnected, on-prem
User Story:
As a user, I want to be able to:
- generate the minimal ISO in the installer when the platform type is set to external/oci
so that I can achieve
- successful cluster installation
- any custom agent features such as network tui should be available when booting from minimal ISO
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a user of the agent-based installer, I want to be able to:
- validate the external platform type in the agent cluster install by providing the external platform type in the install-config.yaml
so that I can achieve
- create agent artifacts ( ISO, PXE files)
Acceptance Criteria:
Description of criteria:
- install-config.yaml accepts the new platform type "external"
- agent-based installer validates the supported platforms
- agent ISO and PXE assets should be created successfully
- Required k8s API support is added
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a user of the agent-based installer, I want to be able to:
- create agent ISO as well as PXE assets by providing the install-config.yaml
so that I can achieve
- create a cluster for external cloud provider platform type (OCI)
Acceptance Criteria:
Description of criteria:
- install-config.yaml accepts the new platform type "external"
- validate install-config so that platformName can only be set to `oci` when platform is external
- agent-based installer validates the supported platforms
- agent ISO and PXE assets should be created successfully
- necessary unit tests and integration tests are added
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Support OpenShift installation in AWS Shared VPC [1] scenario where AWS infrastructure resources (at least the Private Hosted Zone) belong to an account separate from the cluster installation target account.
Goals (aka. expected user outcomes)
As a user I need to use a Shared VPC [1] when installing OpenShift on AWS into an existing VPC. Which will at least require the use of a preexisting Route53 hosted zone where I am not allowed the user "participant" of the shared VPC to automatically create Route53 private zones.
Requirements (aka. Acceptance Criteria):
The Installer is able to successfully deploy OpenShift on AWS with a Shared VPC [1], and the cluster is able to successfully pass osde2e testing. This will include at least the scenario when private hostedZone belongs to different account (Account A) than cluster resources (Account B)
[1] https://docs.aws.amazon.com/vpc/latest/userguide/vpc-sharing.html
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Enable/confirm installation in AWS shared VPC scenario where Private Hosted Zone belongs to an account separate from the cluster installation target account
Why is this important?
- AWS best practices suggest this setup
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
I want
- the installer to check for appropriate permissions based on whether the installation is using an existing hosted zone and whether that hosted zone is in another account
so that I can
- be sure that my credentials have sufficient and minimal permissions before beginning install
Acceptance Criteria:
Description of criteria:
- When specifying platform.aws.hostedZoneRole. Route53:CreateHostedZone and Route53:DeleteHostedZone are not required
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic —
Links:
Enhancement PR: https://github.com/openshift/enhancements/pull/1397
API PR: https://github.com/openshift/api/pull/1460
Ingress Operator PR: https://github.com/openshift/cluster-ingress-operator/pull/928
Background
Feature Goal: Support OpenShift installation in AWS Shared VPC scenario where AWS infrastructure resources (at least the Private Hosted Zone) belong to an account separate from the cluster installation target account.
The ingress operator is responsible for creating DNS records in AWS Route53 for cluster ingress. Prior to the implementation of this epic, the ingress operator doesn't have the capability to add DNS records into an existing Route 53 hosted zone in the shared VPC.
Epic Goal
- Add support to the ingress operator for creating DNS records in preexisting Route53 private hosted zones for Shared VPC clusters
Non-Goals
- Ingress operator support for day-2 operations (i.e. changes to the AWS IAM Role value after installation)
- E2E testing (will be handled by the Installer Team)
Design
As described in the WIP PR https://github.com/openshift/cluster-ingress-operator/pull/928, the ingress operator will consume a new API field that contains the IAM Role ARN for configuring DNS records in the private hosted zone. If this field is present, then the ingress operator will use this account to create all private hosted zone records. The API fields will be described in the Enhancement PR.
The ingress operator code will accomplish this by defining a new provider implementation that wraps two other DNS providers, using one of them to publish records to the public zone and the other to publish records to the private zone.
External DNS Operator Impact
See NE-1299
AWS Load Balancer Operator (ALBO) Impact
See NE-1299
Why is this important?
- Without this ingress operator support, OpenShift users are unable to create DNS records in a preexisting Route53 private hosted zone which means OpenShift users can't share the Route53 component with a Shared VPC
- Shared VPCs are considers AWS best practice
Scenarios
- ...
Acceptance Criteria
- Unit tests must be written and automatically run in CI (E2E tests will be handled by the Installer Team)
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Ingress Operator creates DNS Records in preexisting Route53 private hosted zones for shared VPC Clusters
- Network Edge Team has reviewed all of the related enhancements and code changes for Route53 in Shared VPC Clusters
Dependencies (internal and external)
- Installer Team is adding the new API fields required for enabling sharing Route53 with in Shared VPCs in https://issues.redhat.com/browse/CORS-2613
- Testing this epic requires having access to two AWS account
Previous Work (Optional):
- Significant discussion was done in this thread: https://redhat-internal.slack.com/archives/C68TNFWA2/p1681997102492889?thread_ts=1681837202.378159&cid=C68TNFWA2
- Slack channel #tmp-xcmbu-114
Open questions:
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Develop the implementation for supporting AWS Shared VPC pre-existing Route53 as it is described in the enhancement: https://github.com/openshift/enhancements/pull/1397
Feature Overview (aka. Goal Summary)
During oc login with a token, pasting the token on command line with oc login --token command is insecure. The token is logged in bash history, and appears in a "ps" command when ran precisely at the time the oc login command runs. Moreover, the token gets logged and is searchable by any sysadmin.
Customers/Users would like either the "--web" command, or a command that prompt for a token. There should be no way to pass a secret on a command line with --token command.
For environments where no web browser is available, a "--ask-token" option should be provided that prompts for a token instead of passing it on the command line.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal*
During oc login with a token, pasting the token on command line with oc login --token command is insecure. The token is logged in bash history, and appears in a "ps" command when ran precisely at the time the oc login command runs. Moreover, the token gets logged and is searchable by any sysadmin.
Customers/Users would like either the "--web" command, or a command that prompt for a token. There should be no way to pass a secret on a command line with --token command.
For environments where no web browser is available, a "--ask-token" option should be provided that prompts for a token instead of passing it on the command line.
Why is this important? (mandatory)
Pasting the token on command line with oc login --token command is insecure
Scenarios (mandatory)
Customers/Users would like either the "--web" command. There should be no way to pass a secret on a command line with --token command.
For environments where no web browser is available, a "--ask-token" option should be provided that prompts for a token instead of passing it on the command line.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be "Release Pending"
In order to secure token usage during oc login, we need to add the capability to oc to login using the OAuth2 Authorization Code Grant Flow through a browser. This will be possible by providing a command line option to oc:
oc login --web
Add e2e tests in the OSIN library for redirect URI validation without ports on non-loopback links.
In order for the OAuth2 Authorization Code Grant Flow to work in oc browser login, we need a new OAuthClient that can obtain tokens through [PKCE|https://datatracker.ietf.org/doc/html/rfc7636,] as the existing clients do not have this capability. The new client will be called openshift-cli-client and will have the loopback addresses as valid Redirect URIs.
In order for the OAuth2 Authorization Code Grant Flow to work in oc browser login, the OSIN server must ignore any port used in the Redirect URIs of the flow when the URIs are the loopback addresses. This has already been added to OSIN; we need to update the oauth-server to use the latest version of OSIN in order to make use of this capability.
Review the OVN Interconnect proposal, figure out the work that needs to be done in ovn-kubernetes to be able to move to this new OVN architecture.
Phase-2 of this project in continuation of what was delivered in the earlier release.
Why is this important?
OVN IC will be the model used in Hypershift.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- ...
Why is this important?
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
For interconnect upgrades - i.e when moving from OCP 4.13 to OCP 4.14 where IC is enabled, we do a 2 phase rollout of ovnkube-master and ovnkube-node pods in the openshift-ovn-kubernetes namespace. This is to ensure we have minimum disruption since major architectural components are being brought from control-plane down to the data-plane.
Since its a two phase roll out with each phase taking taking approximately 10mins, we effectively double the time it takes for OVNK component to upgrade thereby increasing the timeout thresholds on AWS.
See https://redhat-internal.slack.com/archives/C050MC61LVA/p1689768779938889 for some more details.
See sample runs:
I have noticed this happening once on GCP:
This has not happened on Azure which has 95mins allowance. So this card tracks the work to increase the timers on AWS/GCP. This was brought up in the TRT team sync that happened yesterday (July 19th 2023) and Scott Dodson has agreed to approve this under the condition that we bring it down back to the current values in release 4.15.
SDN team is confident the time will drop back to normal for future upgrades going from 4.14 -> 4.15 and so on. This will be tracked via https://issues.redhat.com/browse/OTA-999
Work with https://issues.redhat.com/browse/SDN-3654 card to get data from scale team as needed and continue to improvise the numbers.
In the non-IC world, we have centralised DB, running a trace is easy, in IC world, we'd need all the local DBs from each node to even run a pod2pod trace fully else we can only run half traces with one side DB.
Goal of this card:
- Open a PR against `oc` repo to get all dbs (minimum requirement)
Users would desire to create EFA instance MachineSet in the same AWS placement group to get best network performance within that AWS placement group.
The Scope of this Epic is only to support placement groups. Customers will create them.
The customer ask is that placement groups don't need to be created by the OpenShift Container Platform
OpenShift Container Platform only needs to be able to consume them and assign machines out of a machineset to a specific Placement Group.
Users would desire to create EFA instance MachineSet in the same AWS placement group to get best network performance within that AWS placement group.
Note: This Epic was previously connected to https://issues.redhat.com/browse/OCPPLAN-8106 and has been updated to OCPBU-327.
Scope
The Scope of this Epic is only to support placement groups. Customers will create them.
The customer ask is that placement groups don't need to be created by the OpenShift Container Platform
OpenShift Container Platform only needs to be able to consume them and assign machines out of a machineset to a specific Placement Group.
Background
In CAPI, the AWS provider supports the user supplying the name of a pre-existing placement group. Which will then be used to create the instances.
https://github.com/kubernetes-sigs/cluster-api-provider-aws/pull/4273
We need to add the same field to our API and then pass the information through in the same way, to allow users to leverage placement groups.
Steps
- Review the upstream code linked above
- Backport the feature
- Drop old code for placement group controller that is currently disabled
Stakeholders
- Cluster Infra
Definition of Done
- Users may provide a pre-existing placement group name and have their instances created within that placement group
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Console operator should be building up a set of cluster nodes OS types, which he should supply to console, so it renders only operators that could be installed on the cluster.
This will be needed when we will support different OS types on the cluster.
We need to scan through the compute nodes and build a set of supported OS from those. Each node on the cluster has a label for its operating system: e.g. kubernetes.io/os=linux,
AC:
- Implement logic in the console repo
- Add additional flag
- populate the supported OS types into SERVER_FLAGS
- update the filtering logic in the operator hub
1. Proposed title of this feature request
Add a scroll bar for the resource list in the Uninstall Operator pops-up window
2. What is the nature and description of the request?
To make user easy to check the list of all resources
3. Why does the customer need this? (List the business requirements here)
For customers, one operator may have multiple resources, it would be easy for them to check them all in Uninstall Operator pops-up window with the scroll bar
4. List any affected packages or components.
How reproducible:
Steps to Reproduce:
1. 2. 3.
Actual results:
Expected results:
Additional info:
Console operator should be building up a set of cluster nodes OS types, which he should supply to console, so it renders only operators that could be installed on the cluster.
This will be needed when we will support different OS types on the cluster.
We need to scan through the compute nodes and build a set of supported OS from those. Each node on the cluster has a label for its operating system: e.g. kubernetes.io/os=linux,
AC:
- Implement logic in the console-operator that will scan though all the nodes and build a set of all the OS types that the cluster nodes run on and pass it to the console-config.yaml . This set of OS types will be then used by console frontend.
- Add unit and e2e test cases in the console-operator repository.
Goal: OperatorHub/OLM users get a more intuitive UX around discovering and selecting Operator versions to install.
Problem statement: Today it's not possible to install an older version of an Operator unless the user exactly nows the CSV semantic version. This is not exposed however through any API. `packageserver` as of today only shows the latest version per channel.
Why is this important: There are many reasons why a user would want to choose not to install the latest version - whether it's lack of testing or known problems. It should be easy for a user to discovers what versions of an Operator OLM has in its catalogs and update graphs and expose this information in a consumable way to the user.
Acceptance Criteria:
- Users can choose from a list of "available versions" of an Operator based on the "selected channel" on the 'OperatorHub' page in the console.
- Users can see/examine Operator metadata (e.g. descriptions, version, capability level, links, etc) per selected channel/version to confirm the exact version they are going to install on the OperatorHub page.
- The selected channel/version info will be carried over from the 'OperatorHub' page to 'Install Operator' page in the console.
- Note that "installing an older version" means "no automatic update"; hence, when users select a non-latest Operator version, this implies the "Update" field would be changed to "Manual".
- Operator details sidebar data will update based on the selected channel. `createdAt` `containerImage` and `capability level`
Out of scope:
- provide a version selector for updatres in case of existing installed operators
Related info
UX designs: http://openshift.github.io/openshift-origin-design/designs/administrator/olm/select-install-operator-version/
linked OLM jira: https://issues.redhat.com/browse/OPRUN-1399
where you can see the downstream PR: https://github.com/openshift/operator-framework-olm/pull/437/files
specifically: https://github.com/awgreene/operator-framework-olm/blob/f430b2fdea8bedd177550c95ec[…]r/pkg/package-server/apis/operators/v1/packagemanifest_types.go i.e., you can get a list of available versions in PackageChannel stanza from the packagemanifest API
You can reach out to OLM lead Alex Greene for any question regarding this too, thanks
Key Objective
Providing our customers with a single simplified User Experience(Hybrid Cloud Console)that is extensible, can run locally or in the cloud, and is capable of managing the fleet to deep diving into a single cluster.
Why customers want this?
- Single interface to accomplish their tasks
- Consistent UX and patterns
- Easily accessible: One URL, one set of credentials
Why we want this?
- Shared code - improve the velocity of both teams and most importantly ensure consistency of the experience at the code level
- Pre-built PF4 components
- Accessibility & i18n
- Remove barriers for enabling ACM
Phase 2 Goal: Productization of the united Console
- Enable user to quickly change context from fleet view to single cluster view
- Add Cluster selector with “All Cluster” Option. “All Cluster” = ACM
- Shared SSO across the fleet
- Hub OCP Console can connect to remote clusters API
- When ACM Installed the user starts from the fleet overview aka “All Clusters”
- Share UX between views
- ACM Search —> resource list across fleet -> resource details that are consistent with single cluster details view
- Add Cluster List to OCP —> Create Cluster
We need a way to show metrics for workloads running on spoke clusters. This depends on ACM-876, which lets the console discover the monitoring endpoints.
Console operator must discover the external URLs for monitoringConsole operator must pass the URLs and CA files as part of the cluster config to the console backendConsole backend must set up proxies for each endpoint (as it does for the API server endpoints)Console frontend must include the cluster in metrics requests
Open Issues:
We will depend on ACM to create a route on each spoke cluster for the prometheus tenancy service, which is required for metrics for normal users.
Openshift console backend should proxy managed cluster monitoring requests through the MCE cluster proxy addon to prometheus services on the managed cluster. This depends on https://issues.redhat.com/browse/ACM-1188
BU Priority Overview
Initiative: Improve etcd disaster recovery experience (part1)
Goals
The current etcd backup and recovery process is described in our docs https://docs.openshift.com/container-platform/4.12/backup_and_restore/control_plane_backup_and_restore/backing-up-etcd.html
The current process leaves up to the cluster-admin to figure out a way to do consistent backups following the documented procedure.
This feature is part of a progressive delivery to improve the cluster-admin experience for backup and restore of etcd clusters to a healthy state.
Scope of this feature:
- etcd quorum loss (2 node failure) on a 3 nodes OCP control plane
- etcd degradation (1 node failure) on a 3 nodes OCP control plane
Execution Plans
- Improve etcd disaster recovery e2e test coverage
- Design automated backup API. Initial target is local destination
- Should provide a way (e.g. script or tool) for cluster-admin to validate backup files remains valid over time (e.g. account for disk failures corrupting the backup)
- Should document updated manual steps to restore from local backup. These steps should be part of the e2e test coverage.
- Should document manual manual steps to copy backups files to destination outside the cluster. (e.g. ssh copy a cluster admin can use in a CronJob)
Given that we have a controller that processes one time etcd backup requests via the "operator.openshift.io/v1alpha1 EtcdBackup" CR, we need another controller that processes the "config.openshift.io/v1alpha1 Backup" CR so we can have periodic backups according the the schedule in the CR spec.
See https://github.com/openshift/api/pull/1482 for the APIs
The workflow for this controller should roughly be:
- Watches the `config.openshift.io/v1alpha1 Backup` CR as created by an admin
- Creates a CronJob for the specified schedule and timezone that would in turn create `operator.openshift.io/v1alpha1 EtcdBackup` CRs at the desired schedule
- Updates the CronJob for any changes in the schedule or timezone
Along with this controller we would also need to provide the workload or Go command for the pod that is created periodically by the CronJob. This cmd e.g "create-etcdbackup-cr" effectively creates a new `operator.openshift.io/v1alpha1 EtcdBackup` CR via the following workflow:
- Read the Backup CR to get the pvcName (and anything else) required to populate an `EtcdBackup` CR
- Create the `operator.openshift.io/v1alpha1 EtcdBackup` CR
Lastly to fulfill the retention policy (None, number of backups saved, or total size of backups), we can employ the following workflow:
- Have another command e.g "prune-backups" cmd that runs prior to the "create-etcdbackup-cr" command that deletes existing backups per the retention policy.
- This cmd is run before the cmd to create the etcdbackup CR. This could be done via an init container on the CronJob execution pod.
- This would require the backup controller to populate the CronJob spec with the pvc name from the Backup spec that would allowing mounting the PV on the execution pod for pruning the backups in the init container.
Lastly to fulfill the retention policy (None, number of backups saved, or total size of backups), we can employ the following workflow:
- Have another command e.g "prune-backups" cmd that runs prior to the "create-etcdbackup-cr" command that deletes existing backups per the retention policy.
- The retention policy type can either be read from the `config.openshift.io/v1alpha1 Backup` CR
- Or easier yet, the backup controller can pass set the retention policy arg in the CronJob template spec
- This cmd is run before the cmd to create the etcdbackup CR. This could be done via an init container on the CronJob execution pod.
- This would require the backup controller to populate the CronJob spec with the pvc name from the Backup spec that would allowing mounting the PV on the execution pod for pruning the backups in the init container.
See the parent story for more context.
As the first part to this story we need a controller with the following workflow:
- Watches the `config.openshift.io/v1alpha1 Backup` CR as created by an admin
- Creates a CronJob for the specified schedule and timezone that would ultimately create `operator.openshift.io/v1alpha1 EtcdBackup` CRs at the desired schedule
- Updates the CronJob for any changes in the schedule or timezone
Since we also want to preserve a history of successful and failed backup attempts for the periodic config, the CronJob should utilize cronjob history limits to preserve successful and failed jobs.
https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/#jobs-history-limits
To begin with we can set this to a reasonable default of 5 successful and 10 failed jobs.
For testing the automated backups feature we will require an e2e test that validates the backups by ensuring the restore procedure works for a quorum loss disaster recovery scenario.
See the following doc for more background:
https://docs.google.com/document/d/1NkdOwo53mkNBCktV5tkUnbM4vi7bG4fO5rwMR0wGSw8/edit?usp=sharing
This story targets the milestone 2,3 and 4 of the restore test to ensure that the test has the ability to perform a backup and then restore from that backup in a disaster recovery scenario.
While the automated backups API is still in progress, the test will rely on the existing backup script to trigger a backup. Later on when we have a functional backup API behind a feature gate, the test can switch over to using that API to trigger backups.
We're starting with a basic crash-looping member restore first. The quorum loss scenario will be done in ETCD-423.
We should add some basic backup e2e tests into our operator:
- one off backups can be run via API
- periodic backups can be run (also multiple times in succession)
- retention should work
The e2e workflow should be TechPreview enabled already.
For testing the automated backups feature we will require an e2e test that validates the backups by ensuring the restore procedure works for a quorum loss disaster recovery scenario.
See the following doc for more background:
https://docs.google.com/document/d/1NkdOwo53mkNBCktV5tkUnbM4vi7bG4fO5rwMR0wGSw8/edit?usp=sharing
This story targets the first milestone of the restore test to ensure we have a platform agnostic way to be able to ssh access all masters in a test cluster so that we can perform the necessary backup, restore and validation workflows.
The suggested approach is to create a static pod that can do those ssh checks and actions from within the cluster but other alternatives can also be explored as part of this story.
To fulfill one time backup requests there needs to be a new controller that reconciles an EtcdBackup CustomResource (CR) object and executes and saves a one time backup of the etcd cluster.
Similar to the upgradebackupcontroller the controller would be triggered to create a backup pod/job which would save the backup to the PersistentVolume specified by the spec of the EtcdBackup CR object.
The controller would also need to honor the retention policy specified by the EtcdBackup spec and update the status accordingly.
See the following enhancement and API PRs for more details and potential updates to the API and workflow for the one time backup:
https://github.com/openshift/enhancements/pull/1370
https://github.com/openshift/api/pull/1482
< High-Level description of the feature ie: Executive Summary >
Goals
< Who benefits from this feature, and how? What is the difference between today's current state and a world with this feature? >
Requirements
| Requirements | Notes | IS MVP |
< What are we making, for who, and why/what problem are we solving?>
Out of scope
<Defines what is not included in this story>
Dependencies
< Link or at least explain any known dependencies. >
Background, and strategic fit
< What does the person writing code, testing, documenting need to know? >
Assumptions
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Customer Considerations
< Are there specific customer environments that need to be considered (such as working with existing h/w and software)?>
Documentation Considerations
< What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)? >
What does success look like?
< Does this feature have doc impact? Possible values are: New Content, Updates to existing content, Release Note, or No Doc Impact?>
QE Contact
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Impact
< If the feature is ordered with other work, state the impact of this feature on the other work>
Related Architecture/Technical Documents
<links>
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
What's the problem
Currently pipeline builder in dev console directly queries tekton hub APIs for searching tasks. As upstream community and Red Hat is moving to artifacthub, we need to query artifacthub API for searching tasks.
Acceptance criteria
- Update the pipeline builder code so that if the API to retrieve tasks is not available, there will be no errors in the UI.
- Perform a spike to estimate the amount of work it will take to have the pipeline builder use the artifact hub API to retrieve tasks, rather than using the tekton hub API.
Description
Hitting the Artifacthub.io search endpoint fails sometimes due to a CORS error and the Version API endpoint always fails due to a CORS error. So, we need a Proxy to hit the Artifacthub. end point to get the data.
Acceptance Criteria
- Create a proxy to hit the Artifacthub.io endpoint.
Additional Details:
Search endpoint: https://artifacthub.io/docs/api/#/Packages/searchPackages
Version endpoint: https://artifacthub.io/docs/api/#/Packages/getTektonTaskVersionDetails
eg: https://artifacthub.io/api/v1/packages/tekton-task/tekton-catalog-tasks/git-clone/0.9.0
Feature Overview (aka. Goal Summary):
This feature will allow an x86 control plane to operate with compute nodes of type Arm in a HyperShift environment.
Goals (aka. expected user outcomes):
Enable an x86 control plane to operate with an Arm data-plane in a HyperShift environment.
Requirements (aka. Acceptance Criteria):
- The feature must allow an x86 control plane and an Arm data-plane to be used together in a HyperShift environment.
- The feature must provide documentation on how to set up and use the x86 control plane with an Arm data-plane in a HyperShift environment.
- The feature must be tested and verified to work reliably and securely in a production environment.
Customer Considerations:
Customers who require a mix of x86 control plane and Arm data-plane for their HyperShift environment will benefit from this feature.
Documentation Considerations:
- Documentation should include clear instructions on how to set up and use the x86 control plane with an Arm data-plane in a HyperShift environment.
- Documentation will live on docs.openshift.com
Interoperability Considerations:
This feature should not impact other OpenShift layered products and versions in the portfolio.
As a user, I would like to deploy a hypershift cluster to an x86 managed cluster with an arm nodepool.
Starting point:
https://github.com/openshift/hypershift/blob/main/hypershift-operator/controllers/nodepool/nodepool_controller.go
AC:
- Complete necessary code changes to allow ARM AWS nodepools to be added to an x86 managed cluster.
Goal
Numerous partners are asking for ways to pre-image servers in some central location before shipping them to an edge site where they can be configured as an OpenShift cluster: OpenShift-based Appliance.
A number of these cases are a good fit for a solution based on writing an image equivalent to the agent ISO, but without the cluster configuration, to disk at the central location and then configuring and running the installation when the servers reach their final location. (Notably, some others are not a good fit, and will require OpenShift to be fully installed, using the Agent-based installer or another, at the central location.)
While each partner will require a different image, usually incorporating some of their own software to drive the process as well, some basic building blocks of the image pipeline will be widely shared across partners.
Extended documentation
Building Blocks for Agent-based Installer Partner Solutions
Interactive Workflow work (OCPBU-132)
This work must "avoid conflict with the requirements for any future interactive workflow (see Interactive Agent Installer), and build towards it where the requirements coincide. This includes a graphical user interface (future assisted installer consistency).
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Allow the user to use the openshift-installer to generate a configuration ISO that they can attach to a server running the unconfigured agent ISO from
AGENT-558. This would act as alternative to the GUI, effectively leaving the interactive flow and rejoining the automation flow by doing an automatic installation using the configuration contained on the ISO.
Why is this important?
- Helps standardise implementations of the automation flow where an agent ISO image is pre-installed on a physical disk.
Scenarios
- The user purchases hardware with a pre-installed unconfigured agent image. They use openshift-installer to generate a config ISO from an install config, and attach this ISO to the server as virtual media to a group of servers to cause them to install OpenShift and form a cluster.
- The user has a pool of servers that share the same boot mechanism (e.g. PXE). Each server is booted from a common interactive agent image, and automation can install any subset of them as a cluster by attaching the same configuration ISO to each.
- A cloud user could boot a group of VMs using a publicly-available unconfigured agent image (e.g. an AMI), and install them as a cluster by attaching a configuration ISO to them.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
AGENT-556- we'll need to block startup of services until configuration is providedAGENT-558- this won't be useful without an unconfigured image to use it with- AGENT-560 - enables
AGENT-556to block in an image generated withAGENT-558
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Add a new installer subcommand, openshift-install agent create config-image.
The should create a small ISO (i.e. not a CoreOS boot image) containing just the configuration files from the automation flow:
- rendezvousIP config file
- ClusterDeployment manifest
- AgentPullSecret manifest
- AgentClusterInstall manifest
- TLS certs for admin kubeconfig
- password hash for kubeadmin console password
- NMStateConfig
- extra manifests
- hostnames
- hostconfig (roles, root device hints)
- ClusterImageSet manifest (for version verification)
The contents in the disk could be in any format, but should be optimised to make it simple for the service in AGENT-562 to read.
Implement a systemd service in the unconfigured agent ISO (AGENT-558) that watches for disks to be mounted, then searches them for agent installer configuration. If such configuration is found, then copy it to the relevant places in the running system.
The rendezvousIP must be copied last, as the presence of this is what will trigger the services to start (AGENT-556).
To the extent possible, the service should be agnostic as to the method by which the config disk was mounted (e.g. virtual media, USB stick, floppy disk, &c.). It may be possible to get systemd to trigger on volume mount, avoiding the need to poll anything.
The configuration drive must contain:
- rendezvousIP config file
- ClusterDeployment manifest
- AgentPullSecret manifest
- AgentClusterInstall manifest
- TLS certs for admin kubeconfig
- password hash for kubeadmin console password
- ClusterImageSet manifest (for version verification)
it may optionally contain:
- NMStateConfig
- extra manifests
- hostnames
- hostconfig (roles, root device hints)
The ClusterImageSet manifest must match the one already present in the image for the config to be accepted.
Support pd-balanced disk types for GCP deployments
OpenShift installer and Machine API should support creation and management of computing resources with disk type "pd-balanced"
Why does the customer need this?
- pd-balanced are ssd disks with performances comparable to pd-ssd but with a lower price
Epic Goal
- Support pd-balanced disk types for GCP deployments
Why is this important?
- Customers will be able to reduce costs on GCP while using `pd-balanced` disk types with a comparable performance to `pd-ssd` ones.
Scenarios
- Enable `pd-balanced` disk types when deploying a cluster in GCP. Right now only `pd-ssd` and `pd-standard` are supported.
Overview:
- To enable support for pd-balanced disk types during cluster deployment in Google Cloud Platform (GCP) for Openshift Installer.
- Currently, only pd-ssd and pd-standard disk types are supported.
- `pd-balanced` disks on GCP will offer cost reduction and comparable performance to `pd-ssd` disks, providing increased flexibility and performance for deployments.
Acceptance Criteria:
- The Openshift Installer should be updated to include pd-balanced as a valid disk type option in the installer configuration process.
- When pd-balanced disk type is selected during cluster deployment, the installer should handle the configuration of the disks accordingly.
- CI (Continuous Integration) must be running successfully with tests automated.
- Release Technical Enablement details and documents should be provided.
Done Checklist:
- CI is running, tests are automated, and merged.
- Release Enablement Presentation: [link to Feature Enablement Presentation].
- Upstream code and tests merged: [link to meaningful PR or GitHub Issue].
- Upstream documentation merged: [link to meaningful PR or GitHub Issue].
- Downstream build attached to advisory: [link to errata].
- Test plans in Polarion: [link or reference to Polarion].
- Automated tests merged: [link or reference to automated tests].
- Downstream documentation merged: [link to meaningful PR].
Dependencies:
- Google Cloud Platform Account
- Access to GCP ‘Installer’ Project
- Any required permissions, authentication, access controls or CLI needed to provision pd-balanced disk types should be properly configured.
Testing:
- Develop and conduct test cases and scenarios to verify the proper functioning of pd-balanced disk type implementation.
- Address any bugs or issues identified during testing.
Documentation:
- Update documentation to reflect the support for pd-balanced disk types in GCP deployments.
Success Metrics:
- Successful deployment of Openshift clusters using the pd-balanced disk type in GCP.
- Minimal or no disruption to existing functionality and deployment options.
Feature Overview
- Enable user custom RHCOS images location for Installer IPI provisioned OpenShift clusters on Google Cloud and Azure
Goals
- The Installer to accept custom locations for RHCOS images while deploying OpenShift on Google Cloud and Azure as we support already for AWS via `platform.aws.amiID` for control plane and compute nodes.
- As a user, I want to be able to specify a custom RHCOS image location to be used for control plane and compute nodes while deploying OpenShift on Google Cloud and Azure so that I cab be complaint with my company security policies.
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
Background, and strategic fit
Many enterprises have strict security policies where all the software must be pulled from a trusted or private source. For these scenarios the RHCOS image used to bootstrap the cluster is usually coming from shared public locations that some companies don't accept as a trusted source.
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Simplify ARO's workflow by allowing Azure marketplace images to be specified in the `install-config.yaml` for all nodes (compute, control plane, and bootstrap).
Why is this important?
- ARO is a first party Azure service and has a number of requirements/restrictions. These requirements include the following: it must not request anything from outside of Azure and it must consume RHCOS VM images from a trusted source (marketplace).
- At the same time upstream OCP does the following:
-
- It uses quay.io to get container images.
- Uses a random blob as a RHCOS VM image such as this. This VHD blob is then uploaded by the Installer to an Image Gallery in the user’s Storage Account where two boot images are created: a HyperV gen1 and a HyperV gen2. See here.
To meet the requirements ARO team currently does the following as part of the release process:
-
- Mirror container images from quay.io to Azure Container Registry to avoid leaving Azure boundaries.
- Copy VM image from the blob in someone else's Azure subscription into the blob on the subscription ARO team manages and then publish a VM image on Azure Marketplace (publisher: azureopenshift, offer: aro4. See az vm image list --publisher azureopenshift --all). ARO does not bill for these images.
- ARO has to carry their own changes on top of the Installer code to allow them to specify their own images for the cluster deployment.
Scenarios
- ...
Acceptance Criteria
- Custom RHCOS images can be specified in the install-config for compute, controlPlane and defaultMachinePlatform and they are used for the installation instead of the default RHCOS VHD.
Out of scope
- A VHD blob will still be uploaded to the user's Storage Account even though it won't be used during installation. That cannot be changed for now.
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Description of problem:
ARO needs to copy RHCOS image blobs to their own Azure Marketplace offering since, as a first party Azure service, they must not request anything from outside of Azure and must consume RHCOS VM images from a trusted source (marketplace). To meet the requirements ARO team currently does the following as part of the release process: 1. Mirror container images from quay.io to Azure Container Registry to avoid leaving Azure boundaries. 2. Copy VM image from the blob in someone else's Azure subscription into the blob on the subscription ARO team manages and then we publish a VM image on Azure Marketplace (publisher: azureopenshift, offer: aro4. See az vm image list --publisher azureopenshift --all). We do not bill for these images. The usage of Marketplace images in the installer was already implemented as part of CORS-1823. This single line [1] needs to be refactored to enable ARO from the installer code perspective: on ARO we don't need to set type to AzureImageTypeMarketplaceWithPlan. However, in OCPPLAN-7556 and related CORS-1823 it was mentioned that using Marketplace images is out of scope for nodes other than compute. For ARO we need to be able to use marketplace images for all nodes. [1] https://github.com/openshift/installer/blob/f912534f12491721e3874e2bf64f7fa8d44aa7f5/pkg/asset/machines/azure/machines.go#L107
Version-Release number of selected component (if applicable):
4.13
How reproducible:
Always
Steps to Reproduce:
1. Set RHCOS image from Azure Marketplace in the installconfig 2. Deploy a cluster 3.
Actual results:
Only compute nodes use the Marketplace image.
Expected results:
All nodes created by the Installer use RHCOS image coming from Azure Marketplace.
Additional info:
Epic Goal
- As a customer, I need to make sure that the RHCOS image I leverage is coming from a trusted source.
Why is this important?
- For customer who have a very restricted security policies imposed by their InfoSec teams they need to be able to manually specify a custom location for the RHCOS image to use for the Cluster Nodes.
Scenarios
- As a customer, I want to specify a custom location for the RHCOS image to be used for the cluster Nodes
Acceptance Criteria
A user is able to specify a custom location in the Installer manifest for the RHCOS image to be used for bootstrap and cluster Nodes. This is the similar approach we support already for AWS with the compute.platform.aws.amiID option
Previous Work (Optional):
https://issues.redhat.com/browse/CORS-1103
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
Some background on the Licenses field:
https://github.com/openshift/installer/pull/3808#issuecomment-663153787
https://github.com/openshift/installer/pull/4696
So we do not want to allow licenses to be specified (it's up to customers to create a custom image with licenses embedded and supply that to the Installer) when pre-built images are specified (current behaviour). Since we don't need to specify licenses for RHCOs images anymore, the Licenses field is useless and should be deprecated.
Acceptance Criteria:
Description of criteria:
- License field deprecated
- Any dev docs mentioning Licenses is updated.
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a user, I want to be able to:
- Specify a RHCOS image coming from a custom source in the install config to override the installer's internal choice of bootimage
so that I can achieve
- a custom location in the install config for the RHCOS image to use for the Cluster Nodes
Acceptance Criteria:
A user is able to specify a custom location in the Installer manifest for the RHCOS image to be used for bootstrap and cluster Nodes. This is the similar approach we support already for AWS with the compute.platform.aws.amiID option
(optional) Out of Scope:
Engineering Details:
Epic Goal
- Enable the migration from a storage intree driver to a CSI based driver with minimal impact to the end user, applications and cluster
- These migrations would include, but are not limited to:
- CSI driver for Azure (file and disk)
- CSI driver for VMware vSphere
Why is this important?
- OpenShift needs to maintain it's ability to enable PVCs and PVs of the main storage types
- CSI Migration is getting close to GA, we need to have the feature fully tested and enabled in OpenShift
- Upstream intree drivers are being deprecated to make way for the CSI drivers prior to intree driver removal
Scenarios
- User initiated move to from intree to CSI driver
- Upgrade initiated move from intree to CSI driver
- Upgrade from EUS to EUS
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal*
Kubernetes upstream has chosen to allow users to opt-out from CSI volume migration in Kubernetes 1.26 (1.27 PR, 1.26 backport). It is still GA there, but allows opt-out due to non-trivial risk with late CSI driver availability.
We want a similar capability in OCP - a cluster admin should be able to opt-in to CSI migration on vSphere in 4.13. Once they opt-in, they can't opt-out (at least in this epic).
Why is this important? (mandatory)
See an internal OCP doc if / how we should allow a similar opt-in/opt-out in OCP.
Scenarios (mandatory)
Upgrade
- Admin upgrades 4.12 -> 4.13 as usual
- Storage CR has CSI migration disabled (or nil), in-tree volume plugin handles in-tree PVs.
- At the same time, external CCM runs, however, due to kubelet running with –cloud-provider=vsphere, it does not do kubelet’s job.
- Admin can opt-in to CSI migration by editing Storage CR. That enables OPENSHIFT_DO_VSPHERE_MIGRATION env. var. everywhere + runs kubelet with –cloud-provider=external.
- If we have time, it should not be hard to opt out, just remove the env. var + update kubelet cmdline. Storage / in-tree volume plugin will handle in-tree PVs again, not sure about implications on external CCM.
- Once opted-in, it’s not possible to opt out.
- Both with opt-in and without it, the cluster is Upgradeable=true. Admin can upgrade to 4.14, CSI migration will be forced there.
New install
- Admin installs a new 4.13 vSphere cluster, with UPI, IPI, Assisted Installer, or Agent-based Installer.
- During installation, Storage CR is created with CSI migration enabled.
- (We want to have it enabled for a new cluster to enable external CCM and have zonal. This avoids new clusters from having in-tree as default and then having to go through migration later.)
- Resulting cluster has OPENSHIFT_DO_VSPHERE_MIGRATION env. var set + kubelet with –cloud-provider=external + topology support.
- Admin cannot opt-out after installation, we expect that they use CSI volumes for everything.
- If the admin really wants, they can opt-out before installation by adding a Storage install manifest with CSI migration disabled.
EUS to EUS (4.12 -> 4.14)
- Will have CSI migration enabled once in 4.14
- During the upgrade, a cluster will have 4.13 masters with CSI migration disabled (see regular upgrade to 4.13 above) + 4.12 kubelets.
- Once the masters are 4.14, CSI migration is force-enabled there, still, 4.14 KCM + in-tree volume plugin in it will handle in-tree volume attachments required by kubelets that still have 4.12 (that’s what kcm --external-cloud-volume-plugin=vsphere does).
- Once both masters + kubelets are 4.14, CSI migration is force enabled everywhere, in-tree volume plugin + cloud provider in KCM is still enabled by --external-cloud-volume-plugin, but it’s not used.
- Keep in-tree storage class by default
- A CSI storage class is already available since 4.10
- Recommend to switch default to CSI
- Can’t opt out from migration
Dependencies (internal and external) (mandatory)
- We need a new FeatureSet in openshift/api that disables CSIMigrationvSphere feature gate.
- We need kube-apiserver-operator, kube-controller-manager-operator, kube-scheduler-operator, MCO must reconfigure their operands to use in-tree vSphere cloud provider when they see CSIMigrationvSphere FeatureGate disabled.
- We need cloud controller manager operator to disable its operand when it sees CSIMigrationvSphere FeatureGate disabled.
Contributing Teams(and contacts) (mandatory)
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
When CSIMigrationvSphere is disabled, cluster-storage-operator must re-create in-tree StorageClass.
vmware-vsphere-csi-driver-operator's StorageClass must not be marked as the default there (IMO we already have code for that).
This also means we need to fix the Disable SC e2e test to ignore StorageClasses for the in-tree driver. Otherwise we will reintroduce OCPBUGS-7623.
Feature Overview
- Customers want to create and manage OpenShift clusters using managed identities for Azure resources for authentication.
Goals
- A customer using ARO wants to spin up an OpenShift cluster with "az aro create" without needing additional input, i.e. without the need for an AD account or service principal credentials, and the identity used is never visible to the customer and cannot appear in the cluster.
- As an administrator, I want to deploy OpenShift 4 and run Operators on Azure using access controls (IAM roles) with temporary, limited privilege credentials.
Requirements
- Azure managed identities must work for installation with all install methods including IPI and UPI, work with upgrades, and day-to-day cluster lifecycle operations.
- Support HyperShift and non-HyperShift clusters.
- Support use of Operators with Azure managed identities.
- Support in all Azure regions where Azure managed identity is available. Note: Federated credentials is associated with Azure Managed Identity, and federated credentials is not available in all Azure regions.
More details at ARO managed identity scope and impact.
This Section: A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
References
- https://learn.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview
- https://docs.microsoft.com/en-us/azure/active-directory/develop/workload-identity-federation
- https://docs.microsoft.com/en-us/azure/active-directory/develop/workload-identities-overview
- https://learn.microsoft.com/en-us/azure/aks/workload-identity-overview
Epic Goal
- Build list of specific permissions to run Openshift on Azure - Components grant roles, but we need more granularity.
- Determine and document the Azure roles and required permissions for Azure managed identity.
Why is this important?
- Many of our customers have security policies in their organization that restrict credentials to only minimal permissions that conflict with the documented list of permissions needed for OpenShift. Customers need to know the explicit list of permissions minimally needed for deploying and running OpenShift and what they're used for so they can request the right permissions. Without this information, it can/will block adoption of OpenShift 4 in many cases.
Scenarios
- ...
Acceptance Criteria
- Document explicit list of required credential permissions for installing (Day 1) OpenShift on Azure using the IPI and UPI deployment workflows and what each of the permissions are used for.
- Document explicit list of required role and credential permissions for the operation (Day 2) of an OpenShift cluster on Azure and what each of the permissions are used for
- Verify minimum list of permissions for Azure with IPI and UPI installation workflows
- (Day 2) operations of OpenShift on Azure - MUST complete successfully with automated tests
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- Installer [both UPI & IPI Workflows]
- Control Plane
- Kube Controller Manager
- Compute [Managed Identity]
- Cloud API enabled components
- Cloud Credential Operator
- Machine API
- Internal Registry
- Ingress
- ?
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story
As a cluster admin, I want the CCM and Node manager to utilize credentials generated by CCO so that the permissions granted to the identity can be scoped with least privilege on clusters utilizing Azure AD Workload Identity.
Background
The Cloud Controller Manager Operator creates a CredentialsRequest as part of CVO manifests which describes credentials that should be created for the CCM and Node manager to utilize. CCM and the Node Manager do not use the credentials created as a product of the CredentialsRequest in existing "passthrough" based Azure clusters or within Azure AD Workload Identity based Azure clusters. CCM and the Node Manager instead use a system-assigned identity which is attached to the Azure cluster VMs.
The system-assigned identity attached to the VMs is granted the "Contributor" role within the cluster's Azure resource group. In order to use the system-assigned identity, a pod must have sufficient privilege to use the host network to contact the Azure instance metadata service (IMDS).
For Azure AD Workload Identity based clusters, administrators must process the CredentialsRequests extracted from the release image which includes the CredentialsRequest from CCCMO manifests. This CredentialsRequest processing results in the creation of a user-assigned managed identity which is not utilized by the cluster. Additionally, the permissions granted to the identity are currently scoped broadly to grant the "Contributor" role within the cluster's Azure resource group. If the CCM and Node Manager were to utilize the identity then we could scope the permissions granted to the identity to be more granular. It may be confusing to administrators to need to create this unused user-assigned managed identity with broad permissions access.
Steps
- Modify CCM and Node manager deployments to use the CCCMO's Azure credentials injector as an init-container to merge the provided CCO credentials secret with the /etc/kube/cloud.conf file used to configure cloud-provider-azure as used within CCM and the Node Manager. An example of the init-container can be found within the azure-file-csi-driver-operator.
- Validate that the provided credentials are used by CCM and the Node Manager and that they continue to operate normally.
- Scope permissions specified in the CCCMO CredentialsRequest to only those permissions needed for operation rather than "Contributor" within the Azure resource group.
Stakeholders
- <Who is interested in this/where did they request this>
Definition of Done
- CCM and Node Manager use credentials provided by CCO rather than the system-assigned identity attached to the VMs.
- Docs
- <Add docs requirements for this card>
- Testing
- e2e tests validate that the CCM and Node manager operate normally with the credentials provided by CCO.
Update Azure Credentials Request manifest of the Cluster Ingress Operator to use new API field for requesting permissions to enable OCPBU-8?
Update Azure Credentials Request manifest of the Cluster Storage Operator to use new API field for requesting permissions
User Story
As a [user|developer|<other>] I want [some goal] so that [some reason]
<Describes high level purpose and goal for this story. Answers the questions: Who is impacted, what is it and why do we need it?>
Background
<Describes the context or background related to this story>
Steps
- <Add steps to complete this card if appropriate>
Stakeholders
- <Who is interested in this/where did they request this>
Definition of Done
- <Add items that need to be completed for this card>
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
User Story
As a [user|developer|<other>] I want [some goal] so that [some reason]
<Describes high level purpose and goal for this story. Answers the questions: Who is impacted, what is it and why do we need it?>
Background
<Describes the context or background related to this story>
Steps
- <Add steps to complete this card if appropriate>
Stakeholders
- <Who is interested in this/where did they request this>
Definition of Done
- <Add items that need to be completed for this card>
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Add actuator code to satisfy permissions specified in 'Permissions' API field. The implementation should create a new custom role with specified permissions and assign it to the generated user-assigned managed identity along with the predefined roles enumerated in CredReq.RoleBindings. The role we create for the CredentialsRequest should be discoverable so that it can be idempotently updated on re-invocation of ccoctl.
Questions to answer based on lessons learned from custom roles in GCP, assuming that we will create one custom role per identity,
- Does Azure have soft/hard role deletion? ie. are custom roles retained for some period following deletion and if so do deleted roles count towards quota?
- What is the default quota limitation for custom roles in Azure?
- Does it make sense to create a custom role for each identity created based on quota limitations?
- If it doesn't make sense, how can the roles be condensed to satisfy the quota limitations?
Add a new field (DataPermissions) to the Azure Credentials Request CR, and plumb it into the custom role assigned to the generated user-assigned managed identity's data actions.
Update Azure Credentials Request manifest of the Cluster Image Registry Operator to use new API field for requesting permissions
Epic Goal
- CIRO can consume azure workload identity tokens
- CIRO's Azure credential request uses new API field for requesting permissions
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
ACCEPTANCE CRITERIA
- image-registry uses latest openshift/docker-distribution
- CIRO can detect when the creds it gets from CCO are for federated workload identity (the credentials secret will contain a "azure_federated_token_file")
- when using federated workload identity, CIRO adds the "AZURE_FEDERATED_TOKEN_FILE" env var to the image-registry deployment
- when using federated workload identity, CIRO does not add the "REGISTRY_STORAGE_AZURE_ACCOUNTKEY" env var to the image-registry deployment
- the image-registry operates normally when using federated workload identity
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
ACCEPTANCE CRITERIA
- Upstream distribution/distribution uses azure identity sdk 1.3.0
- openshift/docker-distribution uses the latest upstream distribution/distribution (after the above has merged)
- Green CI
- Every storage driver passes regression tests
OPEN QUESTIONS
- Can DefaultAzureCredential be relied on to transparently use workload identities? (in this case the operator would need to export environment varialbes that DefaultAzureCredential expects for workload identities)
- I have tested manually exporting the required env vars and DefaultAzureCredential correctly detects and attempts to authenticate using federated workload identity, so it works as expected.
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
ACCEPTANCE CRITERIA
- CIRO should retrieve the "azure_resourcegroup" from the cluster Infrastructure object instead of the CCO created secret (this key will not be present when workload identity is in use)
- CIRO's CredentialsRequest specifies the service account names (see the: cluster-storage-operator for an example)
- CIRO is able to create storage accounts and containers when configured with azure workload identity.
Epic Goal
- Enable the OpenShift Installer to authenticate using authentication methods supported by both the azure sdk for go and the terraform azure provider
- Future proofing to enable Terraform support for workload identity authentication when it is enabled upstream
Why is this important?
- This ties in to the larger OpenShift goal of: as an infrastructure owner, I want to deploy OpenShift on Azure using Azure Managed Identities (vs. using Azure Service Principal) for authentication and authorization.
- Customers want support for using Azure managed identities in lieu of using an Azure service principal. In the OpenShift documentation, we are directed to use an Azure Service Principal - "Azure offers the ability to create service accounts, which access, manage, or create components within Azure. The service account grants API access to specific services". However, Microsoft and the customer would prefer that we use User Managed Identities to keep from putting the Service Principal and principal password in clear text within the azure.conf file.
- See https://docs.microsoft.com/en-us/azure/active-directory/develop/workload-identity-federation for additional information.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a cluster admin I want to be able to:
- use the managed identity from the installer host VM (running in Azure)
so that I can
- install a cluster without copying credentials to the installer host
Acceptance Criteria:
Description of criteria:
- Installer (azure sdk) & terraform authenticate using identity from host VM (not client secret in file ~/.azure/servicePrincipal.json)
- Cluster credential is handled appropriately (presumably we force manual mode)
Engineering Details:
- Azure session: https://github.com/openshift/installer/blob/master/pkg/asset/installconfig/azure/session.go#L67-L75
- New `azidentity` supports managed identities: https://github.com/Azure/azure-sdk-for-go/blob/main/sdk/azidentity/MIGRATION.md#azidentity-3
- Creating a Managed Identity: https://learn.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/qs-configure-cli-windows-vm
Epic Overview
- Enable customers to create and manage OpenShift clusters using managed identities for Azure resources for authentication.
- A customer using ARO wants to spin up an OpenShift cluster with "az aro create" without needing additional input, i.e. without the need for an AD account or service principal credentials, and the identity used is never visible to the customer and cannot appear in the cluster.
Epic Goal
- A customer creates an OpenShift cluster ("az aro create") using Azure managed identity.
- Azure managed identities must work for installation with all install methods including IPI and UPI, work with upgrades, and day-to-day cluster lifecycle operations.
- After Azure failed to implement workable golang API changes after deprecation of their old API, we have removed mint mode and work entirely in passthrough mode. Azure has plans to implement pod/workload identity similar to how they have been implemented in AWS and GCP, and when this feature is available, we should implement permissions similar to AWS/GCP
- This work cannot start until Azure have implemented this feature - as such, this Epic is a placeholder to track the effort when available.
Why is this important?
- Microsoft and the customer would prefer that we use Managed Identities vs. Service Principal (which requires putting the Service Principal and principal password in clear text within the azure.conf file).
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
- https://github.com/openshift/azure-file-csi-driver-operator/pull/62
- https://github.com/openshift/azure-file-csi-driver-operator/pull/54
- https://github.com/openshift/azure-file-csi-driver-operator/pull/53
- https://github.com/openshift/cluster-cloud-controller-manager-operator/pull/245
- https://github.com/openshift/cluster-storage-operator/pull/372
- Request brew and delivery repositories
- Request ART image build and promotion for Azure AD pod identity webhook image
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
Create a config secret in the openshift-cloud-credential-operator namespace which contains the AZURE_TENANT_ID to be used for configuring the Azure AD pod identity webhook deployment.
These docs should cover:
- A general overview of the feature, what changes are made to Azure credentials secrets and how to install a new cluster.
- A usage guide of `ccoctl azure` commands to create/manage infra required for Azure workload identity.
See existing documentation for:
This effort is dependent on the completion of work for CCO-187, and effort in dependent modules is planned to be worked on by the CCO team unless individual repo owners can help. Operators owners/teams will be expected to review merge requests and complete appropriate QE effort for an openshift release.
- azure-sdk-for-go module dependency updated to support workload identity federation.
- Support for workload identity federation is not yet complete for azure-sdk-for-go. Support is being tracked in the following issues,
- Mount the OIDC token in the operator pod. This needs to go in the deployment. See example from addition to the cluster-image-registry-operator here
Feature Overview
RHEL CoreOS should be updated to RHEL 9.2 sources to take advantage of newer features, hardware support, and performance improvements.
Requirements
- RHEL 9.x sources for RHCOS builds starting with OCP 4.13 and RHEL 9.2.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
9.2 Preview via LayeringNo longer necessary assuming we stay the course of going all in on 9.2
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Epic Goal
- The Kernel API was updated for RHEL 9, so the old approach of setting the `sched_domain` in `/sys/kernel` is no longer available. Instead, cgroups have to be worked with directly.
- Both CRI-O and PAO need to be updated to set the cpuset of containers and other processes correctly, as well as set the correct value for sched_load_balance
Why is this important?
- CPU load balancing is a vital piece of real time execution for processes that need exclusive access to a CPU. Without this, CPU load balancing won't work on RHEL 9 with Openshift 4.13
Scenarios
- As a developer on Openshift, I expect my pods to run with exclusive CPUs if I set the PAO configuration correctly
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Part of setting CPU load balancing on RHEL 9 involves disabling sched_load_balance on cgroups that contain a cpuset that should be exclusive. The PAO may be required to be responsible for this piece
This is the Epic to track the work to add RHCOS 9 in OCP 4.13 and to make OCP use it by default.
CURRENT STATUS: Landed in 4.14 and 4.13
Testing with layering
Another option given an existing e.g. 4.12 cluster is to use layering. First, get a digested pull spec for the current build:
$ skopeo inspect --format "{{.Name}}@{{.Digest}}" -n docker://quay.io/openshift-release-dev/ocp-v4.0-art-dev:4.13-9.2
quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:b4cc3995d5fc11e3b22140d8f2f91f78834e86a210325cbf0525a62725f8e099
Create a MachineConfig that looks like this:
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: worker-override
spec:
osImageURL: <digested pull spec>
If you want to also override the control plane, create a similar one for the master role.
We don't yet have auto-generated release images. However, if you want one, you can ask cluster bot to e.g. "launch https://github.com/openshift/machine-config-operator/pull/3485" with options you want (e.g. "azure" etc.) or just "build https://github.com/openshift/machine-config-operator/pull/3485" to get a release image.
STATUS: Code is merged for 4.13 and is believed to largely solve the problem.
Description of problem:
Upgrades to from OpenShift 4.12 to 4.13 will also upgrade the underlying RHCOS from 8.6 to 9.2. As part of that the names of the network interfaces may change. For example `eno1` may be renamed to `eno1np0`. If a host is using NetworkManager configuration files that rely on those names then the host will fail to connect to the network when it boots after the upgrade. For example, if the host had static IP addresses assigned it will instead boot using IP addresses assigned via DHCP.
Version-Release number of selected component (if applicable):
4.13
How reproducible:
Always.
Steps to Reproduce:
1. Select hardware (or VMs) that will have different network interface names in RHCOS 8 and RHCOS 9, for example `eno1` in RHCOS 8 and `eno1np0` in RHCOS 9. 1. Install a 4.12 cluster with static network configuration using the `interface-name` field of NetworkManager interface configuration files to match the configuration to the network interface. 2. Upgrade the cluster to 4.13.
Actual results:
The NetworkManager configuration files are ignored because they don't longer match the NIC names. Instead the NICs get new IP addresses from DHCP.
Expected results:
The NetworkManager configuration files are updated as part of the upgrade to use the new NIC names.
Additional info:
Note this a hypothetical scenario. We have detected this potential problem in a slightly different scenario where we install a 4.13 cluster with the assisted installer. During the discovery phase we use RHCOS 8 and we generate the NetworkManager configuration files. Then we reboot into RHCOS 9, and the configuration files are ignored due to the change in the NICs. See MGMT-13970 for more details.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Create a new platform type, working name "External", that will signify when a cluster is deployed on a partner infrastructure where core cluster components have been replaced by the partner. “External” is different from our current platform types in that it will signal that the infrastructure is specifically not “None” or any of the known providers (eg AWS, GCP, etc). This will allow infrastructure partners to clearly designate when their OpenShift deployments contain components that replace the core Red Hat components.
This work will require updates to the core OpenShift API repository to add the new platform type, and then a distribution of this change to all components that use the platform type information. For components that partners might replace, per-component action will need to be taken, with the project team's guidance, to ensure that the component properly handles the "External" platform. These changes will look slightly different for each component.
To integrate these changes more easily into OpenShift, it is possible to take a multi-phase approach which could be spread over a release boundary (eg phase 1 is done in 4.X, phase 2 is done in 4.X+1).
Phase 1
- Write platform “External” enhancement.
- Evaluate changes to cluster capability annotations to ensure coverage for all replaceable components.
- Meet with component teams to plan specific changes that will allow for supplement or replacement under platform "External".
Phase 2
- Update OpenShift API with new platform and ensure all components have updated dependencies.
- Update capabilities API to include coverage for all replaceable components.
- Ensure all Red Hat operators tolerate the "External" platform and treat it the same as "None" platform.
Phase 3
- Update components based on identified changes from phase 1
- Update Machine API operator to run core controllers in platform "External" mode.
Why is this important?
- As partners begin to supplement OpenShift's core functionality with their own platform specific components, having a way to recognize clusters that are in this state helps Red Hat created components to know when they should expect their functionality to be replaced or supplemented. Adding a new platform type is a significant data point that will allow Red Hat components to understand the cluster configuration and make any specific adjustments to their operation while a partner's component may be performing a similar duty.
- The new platform type also helps with support to give a clear signal that a cluster has modifications to its core components that might require additional interaction with the partner instead of Red Hat. When combined with the cluster capabilities configuration, the platform "External" can be used to positively identify when a cluster is being supplemented by a partner, and which components are being supplemented or replaced.
Scenarios
- A partner wishes to replace the Machine controller with a custom version that they have written for their infrastructure. Setting the platform to "External" and advertising the Machine API capability gives a clear signal to the Red Hat created Machine API components that they should start the infrastructure generic controllers but not start a Machine controller.
- A partner wishes to add their own Cloud Controller Manager (CCM) written for their infrastructure. Setting the platform to "External" and advertising the CCM capability gives a clear to the Red Hat created CCM operator that the cluster should be configured for an external CCM that will be managed outside the operator. Although the Red Hat operator will not provide this functionality, it will configure the cluster to expect a CCM.
Acceptance Criteria
Phase 1
- Partners can read "External" platform enhancement and plan for their platform integrations.
- Teams can view jira cards for component changes and capability updates and plan their work as appropriate.
Phase 2
- Components running in cluster can detect the “External” platform through the Infrastructure config API
- Components running in cluster react to “External” platform as if it is “None” platform
- Partners can disable any of the platform specific components through the capabilities API
Phase 3
- Components running in cluster react to the “External” platform based on their function.
- for example, the Machine API Operator needs to run a set of controllers that are platform agnostic when running in platform “External” mode.
- the specific component reactions are difficult to predict currently, this criteria could change based on the output of phase 1.
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- Phase 1 requires talking with several component teams, the specific action that will be needed will depend on the needs of the specific component. At the least the components need to treat platform "External" as "None", but there could be more changes depending on the component (eg Machine API Operator running non-platform specific controllers).
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- As defined in the part (
OCPBU-5), this epic is about adding the new "External" platform type and ensuring that the OpenShift operators which react to platform types treat the "External" platform as if it were a "None" platform. - Add an end-to-end test to exercise the "External" platform type
Why is this important?
- This work lays the foundation for partners and users to customize OpenShift installations that might replace infrastructure level components.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Background
As described in the external platform enhancement , the cluster-cloud-controller-manager-opeartor should be modified to react to the external platform type in the same manner as platform none.
Steps
- add an extra clause to the platform switch that will group "External" with "None"
Stakeholders
- openshift eng
Definition of Done
- CCCMO behaves as if platform None when External is selected
- Docs
- developer docs for CCCMO should be updated
- Testing
- see
OCPCLOUD-1782
Background
As described in the external platform enhancement , the machine-api-operator should be modified to react to the external platform type in the same manner as platform none.
Steps
- add an extra clause to the platform switch that will group "External" with "None"
Stakeholders
- openshift eng
Definition of Done
- MAO behaves as if platform None when External is selected
- Docs
- developer docs for MAO should be updated
- Testing
- see
OCPCLOUD-1782
Feature Overview
Create a Azure cloud specific spec.resourceTags entry in the infrastructure CRD. This should create and update tags (or labels in Azure) on any openshift cloud resource that we create and manage. The behaviour should also tag existing resources that do not have the tags yet and once the tags in the infrastructure CRD are changed all the resources should be updated accordingly.
Tag deletes continue to be out of scope, as the customer can still have custom tags applied to the resources that we do not want to delete.
Due to the ongoing intree/out of tree split on the cloud and CSI providers, this should not apply to clusters with intree providers (!= "external").
Once confident we have all components updated, we should introduce an end2end test that makes sure we never create resources that are untagged.
Goals
- Functionality on Azure Tech Preview
- inclusion in the cluster backups
- flexibility of changing tags during cluster lifetime, without recreating the whole cluster
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
List any affected packages or components.
- Installer
- Cluster Infrastructure
- Storage
- Node
- NetworkEdge
- Internal Registry
- CCO
Remove code references related to Azure Tags is for TechPreview in below list
Create a severity warning alert to alert to admin that there is packet loss occurring due to failed ovs vswitchd lookups. This may occur if vswitchd is cpu constrained and there are also numerous lookups.
Use metric ovs_vswitchd_netlink_overflow which shows netlink messages dropped by the vswitchd daemon due to buffer overflow in userspace.
For the kernel equivalent, use metric ovs_vswitchd_dp_flows_lookup_lost . Both metrics usually have the same value but may differ if vswitchd may restart.
Both these metrics should be aggregate into a single alert if the value has increased recently.
DoD: QE test case, code merged to CNO, metrics document updated ( https://docs.google.com/document/d/1lItYV0tTt5-ivX77izb1KuzN9S8-7YgO9ndlhATaVUg/edit )
< High-Level description of the feature ie: Executive Summary >
Goals
< Who benefits from this feature, and how? What is the difference between today’s current state and a world with this feature? >
Requirements
| Requirements | Notes | IS MVP |
< What are we making, for who, and why/what problem are we solving?>
Out of scope
<Defines what is not included in this story>
Dependencies
< Link or at least explain any known dependencies. >
Background, and strategic fit
< What does the person writing code, testing, documenting need to know? >
Assumptions
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Customer Considerations
< Are there specific customer environments that need to be considered (such as working with existing h/w and software)?>
Documentation Considerations
< What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)? >
What does success look like?
< Does this feature have doc impact? Possible values are: New Content, Updates to existing content, Release Note, or No Doc Impact?>
QE Contact
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Impact
< If the feature is ordered with other work, state the impact of this feature on the other work>
Related Architecture/Technical Documents
<links>
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
Problem:
There's no way in the UI for the cluster admin to
- change the default timeout period for the Web Terminal for all users
- select an image from an image repository to be used as the default image for the Web Terminal for all users
Goal:
Expose the ability for cluster admins to provide customization for all web terminal users through the UI which is available in wtoctl
Why is it important?
Acceptance criteria:
- Cluster admin should be able to change the default timeout period for all new instances of the Web Terminal (it won't change settings)
- Cluster admin should be able to provide a new image as the default image for all new instances of the Web Terminal (it won't change settings)
Dependencies (External/Internal):
Design Artifacts:
Exploration:
Questions:
- Where will this information be shared?
- What CLI is used to accomplish this today? Get link to docs
Description
This is the follow up story for PR - https://github.com/openshift/console/pull/12718. Couple of tests, which are dependent on YAML are added as manual tests. Need to add proper tests for that.
Acceptance Criteria
- Add automated tests instead of manual for PR - https://github.com/openshift/console/pull/12718.
After submit, switch to developer tab and comeback to web terminal tab and see the populated values. This should reflect the newly updated values. - Remove the delays added(cy.wait) in customization-of-web-terminal.ts[ |https://github.com/openshift/console/pull/12718/files#diff-bea278ba2b0622e97023a25a89e91b2194e3ba73824d81ea4b08046558ba8718]and make sure all the tests are passing
- Write test cases for utils updatedWebTerminalExec and updatedWebTerminalTooling
Additional Details:
Refer PR - https://github.com/openshift/console/pull/12718 for more details
Description
Update the help texts in initialize Terminal page as below
**
1. "This Project will be used to initialize your command line terminal" to "Project used to initialize your command line terminal"
2. "Set timeout for the terminal." to "Pod timeout for your command line terminal"
3. "Set custom image for the terminal." to "Custom image used for your command line terminal
Acceptance Criteria
Update the help texts in initialize Terminal page as below
**
1. "This Project will be used to initialize your command line terminal" to "Project used to initialize your command line terminal"
2. "Set timeout for the terminal." to "Pod timeout for your command line terminal"
3. "Set custom image for the terminal." to "Custom image used for your command line terminal
Additional Details:
Description
Allow cluster admin to provide default image and/or timeout period for all cluster users
Acceptance Criteria
- Add Web Terminal tab in Cluster Configuration page under Developer tab
- This tab should be visible only to cluster admins
- Add 2 fields, one is to change default timeout and other is to change default image
- Default values should be pre-populated in above fields from
Default Timeout - WEB_TERMINAL_IDLE_TIMEOUT environment variable's value in the web-terminal-exec DevWorkspaceTemplate Default Image - .spec.components[].container.image field in the web-terminal-tooling DevWorkspaceTemplate
5. Once user change this and save, need to update the same above resources(refer comment in epic https://issues.redhat.com/browse/ODC-7119 for more details)
6. If the user has read access to DevWorkspaceTemplate, then save button should not be enabled and if user don't have read access to DevWorkspaceTemplate then no need to show web terminal tab in configuration page
7. Add e2e tests
Additional Details:
Timeout and Image component should be similar to web terminal components (attached in ticket).
refer comment in epic https://issues.redhat.com/browse/ODC-7119 for more details
Overview
HyperShift is being consumed by multiple providers. As a result, the need for documentation increases especially around infrastructure/hardware/resource requirements, networking, ..
Goal
Before the GA of Hosted Control Planes, we need to know/document:
- What Infrastructure is managed by HCP?
- What are the hardware requirements/prereqs for a hosted cluster?
- What infrastructure resources get created by Kubernetes/OpenShift during hosted cluster lifecycle?
- What networking requirements exist, e.g., open ports?
- What are storage requirements?
- What default quota limits are there (e.g., EIP default limits per region)? Do we tell the user to increase them in production?
DoD
The above questions are answered for all platforms we support, i.e., we need to answer for
- [x] AWS
- [x] Baremetal via the agent
- [x] KubeVirt
Feature Overview (aka. Goal Summary)
Add support of NAT Gateways in Azure while deploying OpenShift on this cloud to manage the outbound network traffic and make this the default option for new deployments
Goals (aka. expected user outcomes)
While deploying OpenShift on Azure the Installer will configure NAT Gateways as the default method to handle the outbound network traffic so we can prevent existing issues on SNAT Port Exhaustion issue related to the configured outboundType by default.
Requirements (aka. Acceptance Criteria):
The installer will use the NAT Gateway object from Azure to manage the outbound traffic from OpenShift.
The installer will create a NAT Gateway object per AZ in Azure so the solution is HA.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Background
Using NAT Gateway for egress traffic is the recommended approach from Microsoft
This is also a common ask from different enterprise customers as with the actual solution used by OpenShift for outbound traffic management in Azure they are hitting SNAT Port Exhaustion issues.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- Control Plane hosts should allow NAT Gateway for Internet egress for purposes of pulling images etc
Why is this important?
- Our current architecture is limited to the Azure feature set from when OCP 4.x went GA on Azure and NAT Gateways were not an option
- Today the preferred solution is to use a NAT Gateway for egress, see https://learn.microsoft.com/en-us/azure/load-balancer/load-balancer-outbound-connections#scenarios
Scenarios
- Install a new cluster, control plane hosts access the Internet via NAT Gateway rather than via the public load balancer
- Install a new cluster, with user defined routing, control plane hosts access Internet via previously available UDR
- Upgraded clusters maintain their existing architecture
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Open questions::
- Control plane hosts are a must, but likely should just NAT gateway for all, need to understand pros/cons of doing so
- It'd be nice to understand what a potential migration for legacy clusters to the new architecture looks like and what options we have to automate that in a non disruptive manner.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a administrator, I want to be able to:
- Allow NAT Gateway as outboundType for clusters in Azure
so that I can achieve
- Outbound access without exhausting SNAT ports
Acceptance Criteria:
Description of criteria:
- NAT gateway as an outboundType in install-config
Engineering Details:
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
You can use the oc-mirror OpenShift CLI (oc) plugin to mirror all required OpenShift Container Platform content and other images to your mirror registry by using a single tool. It provides the following features:
- Provides a centralized method to mirror OpenShift Container Platform releases, Operators, helm charts, and other images.
- Maintains update paths for OpenShift Container Platform and Operators.
- Uses a declarative image set configuration file to include only the OpenShift Container Platform releases, Operators, and images that your cluster needs.
- Performs incremental mirroring, which reduces the size of future image sets.
This feature is track bring the oc mirror plugin to IBM Power and IBM zSystem architectures
Goals (aka. expected user outcomes)
Bring the oc mirror plugin to IBM Power and IBM zSystem architectures
Requirements (aka. Acceptance Criteria):
oc mirror plugin on IBM Power and IBM zSystems should behave exactly like it does on x86 platforms.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
If this Epic is an RFE, please complete the following questions to the best of your ability:
Q1: Proposed title of this RFE
Support for oc mirror plugin (parity to x86)
Q2: What is the nature and description of the RFE?
oc mirror plugin will be the tool for mirror plugin
Q3: Why does the customer need this? (List the business requirements here)
install disconnected cluster without having x86 nodes available to manage the disconnected installation
Q4: List any affected packages or components
Quay on the platform needs be available for saving the images.
- Ensure that oc-mirror plugin is buildable on P and that necessary PRs are filed to enable building alongside x86.
- Populate https://mirror.openshift.com/pub/openshift-v4/ppc64le/clients/ocp/stable/ with ppc64le binary, so it is visible and downloadable from https://console.redhat.com/openshift/downloads#tool-oc-mirror-plugin
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned components should be running on Kubernetes 1.27
- This includes
- The cluster autoscaler (+operator)
- Machine API operator
- Machine API controllers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Machine API controllers for:
- Cloud Controller Manager Operator
- Cloud controller managers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Cloud controller managers for:
- Cluster Machine Approver
- Cluster API Actuator Package
- Control Plane Machine Set Operator
Why is this important?
- ...
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.14 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
Why is this important? (mandatory)
What are the benefits to the customer or Red Hat? Does it improve security, performance, supportability, etc? Why is work a priority?
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
- https://github.com/openshift/cluster-kube-apiserver-operator/pull/1469
- https://github.com/openshift/cluster-kube-controller-manager-operator/pull/713
- https://github.com/openshift/cluster-kube-scheduler-operator/pull/472
- https://github.com/openshift/kubernetes/pull/1595
- https://github.com/openshift/kubernetes/pull/1583
- https://github.com/openshift/kubernetes/pull/1558
- https://github.com/openshift/origin/pull/27970
- https://github.com/openshift/origin/pull/27894
Epic Goal
- Update all images that we ship with OpenShift to the latest upstream releases and libraries.
- Exact content of what needs to be updated will be determined as new images are released upstream, which is not known at the beginning of OCP development work. We don't know what new features will be included and should be tested and documented. Especially new CSI drivers releases may bring new, currently unknown features. We expect that the amount of work will be roughly the same as in the previous releases. Of course, QE or docs can reject an update if it's too close to deadline and/or looks too big.
Traditionally we did these updates as bugfixes, because we did them after the feature freeze (FF). Trying no-feature-freeze in 4.12. We will try to do as much as we can before FF, but we're quite sure something will slip past FF as usual.
Why is this important?
- We want to ship the latest software that contains new features and bugfixes.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
This includes ibm-vpc-node-label-updater!
(Using separate cards for each driver because these updates can be more complicated)
Update all OCP and kubernetes libraries in storage operators to the appropriate version for OCP release.
This includes (but is not limited to):
- Kubernetes:
- client-go
- controller-runtime
- OCP:
- library-go
- openshift/api
- openshift/client-go
- operator-sdk
Operators:
- aws-ebs-csi-driver-operator
- aws-efs-csi-driver-operator
- azure-disk-csi-driver-operator
- azure-file-csi-driver-operator
- openstack-cinder-csi-driver-operator
- gcp-pd-csi-driver-operator
- gcp-filestore-csi-driver-operator
- csi-driver-manila-operator
- vmware-vsphere-csi-driver-operator
- alibaba-disk-csi-driver-operator
- ibm-vpc-block-csi-driver-operator
- csi-driver-shared-resource-operator
- ibm-powervs-block-csi-driver-operator
- cluster-storage-operator
- cluster-csi-snapshot-controller-operator
- local-storage-operator
- vsphere-problem-detector
EOL, do not upgrade:
- github.com/oVirt/csi-driver-operator
- https://github.com/openshift/alibaba-disk-csi-driver-operator/pull/51
- https://github.com/openshift/aws-ebs-csi-driver-operator/pull/222
- https://github.com/openshift/azure-disk-csi-driver-operator/pull/81
- https://github.com/openshift/azure-file-csi-driver-operator/pull/57
- https://github.com/openshift/cluster-csi-snapshot-controller-operator/pull/151
- https://github.com/openshift/csi-driver-manila-operator/pull/182
- https://github.com/openshift/gcp-pd-csi-driver-operator/pull/70
- https://github.com/openshift/ibm-vpc-block-csi-driver-operator/pull/57
- https://github.com/openshift/openstack-cinder-csi-driver-operator/pull/115
- https://github.com/openshift/vmware-vsphere-csi-driver-operator/pull/155
- https://github.com/openshift/vsphere-problem-detector/pull/112
Update all CSI sidecars to the latest upstream release from https://github.com/orgs/kubernetes-csi/repositories
- external-attacher
- external-provisioner
- external-resizer
- external-snapshotter
- node-driver-registrar
- livenessprobe
Corresponding downstream repos have `csi-` prefix, e.g. github.com/openshift/csi-external-attacher.
This includes update of VolumeSnapshot CRDs in cluster-csi-snapshot-controller- operator assets and client API in go.mod. I.e. copy all snapshot CRDs from upstream to the operator assets + go get -u github.com/kubernetes-csi/external-snapshotter/client/v6 in the operator repo.
- https://github.com/openshift/csi-external-attacher/pull/54
- https://github.com/openshift/csi-external-provisioner/pull/65
- https://github.com/openshift/csi-external-resizer/pull/141
- https://github.com/openshift/csi-external-snapshotter/pull/101
- https://github.com/openshift/csi-livenessprobe/pull/44
- https://github.com/openshift/csi-node-driver-registrar/pull/46
Epic Goal
- The goal of this epic is to upgrade all OpenShift and Kubernetes components that MCO uses to v1.27 which will keep it on par with rest of the OpenShift components and the underlying cluster version.
Why is this important?
- Uncover any possible issues with the openshift/kubernetes rebase before it merges.
- MCO continues using the latest kubernetes/OpenShift libraries and the kubelet, kube-proxy components.
- MCO e2e CI jobs pass on each of the supported platform with the updated components.
Acceptance Criteria
- All stories in this epic must be completed.
- Go version is upgraded for MCO components.
- CI is running successfully with the upgraded components against the 4.14/master branch.
Dependencies (internal and external)
- ART team creating the go 1.20 image for upgrade to go 1.20.
- OpenShift/kubernetes repository downstream rebase PR merge.
Open questions::
- Do we need a checklist for future upgrades as an outcome of this epic?-> yes, updated below.
Done Checklist
- Step 1 - Upgrade go version to match rest of the OpenShift and Kubernetes upgraded components.
- Step 2 - Upgrade Kubernetes client and controller-runtime dependencies (can be done in parallel with step 3)
- Step 3 - Upgrade OpenShift client and API dependencies
- Step 4 - Update kubelet and kube-proxy submodules in MCO repository
- Step 5 - CI is running successfully with the upgraded components and libraries against the master branch.
Please review the following PR: https://github.com/openshift/machine-config-operator/pull/3598
The PR has been automatically opened by ART (#aos-art) team automation and indicates
that the image(s) being used downstream for production builds are not consistent
with the images referenced in this component's github repository.
Differences in upstream and downstream builds impact the fidelity of your CI signal.
If you disagree with the content of this PR, please contact @release-artists
in #aos-art to discuss the discrepancy.
Closing this issue without addressing the difference will cause the issue to
be reopened automatically.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned components should be running on Kubernetes 1.26
- This includes
- The cluster autoscaler (+operator)
- Machine API operator
- Machine API controllers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Machine API controllers for:
- Cloud Controller Manager Operator
- Cloud controller managers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Cloud controller managers for:
- Cluster Machine Approver
- Cluster API Actuator Package
- Control Plane Machine Set Operator
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.13 release, dependencies need to be updated to 1.26. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.13 release, dependencies need to be updated to 1.26. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.13 release, dependencies need to be updated to 1.26. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.13 release, dependencies need to be updated to 1.26. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.13 release, dependencies need to be updated to 1.26. This should be done by rebasing/updating as appropriate for the repository
Feature Overview
Agent-based installer requires to boot the generated ISO on the target nodes manually. Support for PXE booting will allow customers to automate their installations via their DHCP/PXE infrastructure.
This feature allows generating installation ISOs ready to add to a customer-provided DHCP/PXE infrastructure.
Goals
As an OpenShift installation admin I want to PXE-boot the image generated by the openshift-install agent subcommand
Why is this important?
We have customers requesting this booting mechanism to make it easier to automate the booting of the nodes without having to actively place the generated image in a bootable device for each host.
Epic Goal
As an OpenShift installation admin I want to PXE-boot the image generated by the openshift-install agent subcommand
Why is this important?
We have customers requesting this booting mechanism to make it easier to automate the booting of the nodes without having to actively place the generated image in a bootable device for each host.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
As a user of the Agent-based Installer(ABI), I want to be able to perform the customizations via agent-tui in case of PXE booting so that I can modify network settings.
Implementation details:
Create a new baseImage asset that gets inherited by agentImage and agentpxefiles. The baseImage prepares the initrd along with the necessary ignition and the network tui which is now read by agentImage and agentpxefiles.
ARM kernels are compressed with gzip, but most versions of ipxe cannot handle this (it's not clear what happens with raw pxe). See https://github.com/coreos/fedora-coreos-tracker/issues/1019 for more info.
If the platform is aarch64 we'll need to decompress the kernel like we do in https://github.com/openshift/machine-os-images/commit/1ed36d657fa3db55fc649761275c1f89cd7e8abe
The new command {{agent create pxe-files }} reads - pxe-base-url from the agent-config.yaml. The field will be optional in the yaml file. If the URL is provided, then the command will generate an ipxe script specific to the given URL.
Currently, we have the kernel parameters in the iPXE script statically defined from what Assisted Service generates. If the default parameters were to change in RHCOS that would be problematic. Thus, it would be much better if we were to extract them from the ISO.
The kernel parameters in the ISO are defined in EFI/redhat/grub.cfg (UEFI) and /isolinux/isolinux.cfg (legacy boot)
Epic Goal
Support deploying multi-node clusters using platform none.
Why is this important?
As of Jan 2023 we have almost 5,000 clusters reported using platform none installed on-prem (metal, vmware or other hypervisors with no platform integration) out of a total of about 12,000 reported clusters installed on-prem.
Platform none is desired by users to be able to install clusters across different host platforms (e.g. mixing virtual and physical) where Kubernetes platform integration isn't a requirement.
A goal of the Agent-Based Installer is to help users who currently can only deploy their topologies with UPI to be able to use the agent-based installer and get a simpler user experience while keeping all their flexibility.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Currently there are validation checks for platform None in OptionalInstallConfig that limits the None platform to 1 control plane replica, 0 compute replicas, and the NetworkType to OVNKubernetes.
These validation should be removed so that the None platform can be installed on clusters of any configuration.
Acceptance Criteria:
- SNO cluster should still continue to work.
- SNO validation should still check only OVNKubernetes network type is allowed
- A compact or HA cluster can be installed with platform None, given the user has configured and deployed an external load balancer.
Feature Overview (aka. Goal Summary)
Add support to the Installer to make the S3 bucket deletion process during cluster bootstrap on AWS optional.
Goals (aka. expected user outcomes)
Allow the user to opt-out for deleting the S3 bucket created during the cluster bootstrap on AWS.
Requirements (aka. Acceptance Criteria):
The user will be able to opt-out from deleting the S3 bucket created during the cluster bootstrap on AWS via the install-config manifest so the Installer will not try to delete this resource when destroying the bootstrap instance and the S3 bucket.
The actual behavior will remain the default behavior while deploying OpenShift on AWS and both the bootstrap instance and the S3 bucket will be removed unless the user has opted-out for this via the install-config manifest.
Background
Some ROSA customers have SCP policies that prevent the deletion of any S3 bucket preventing ROSA adoption for these customers.
Documentation Considerations
There will be documentation required for this feature to explain how to prevent the Installer to remove the S3 bucket as well as an explanation on the security concerns while doing this since sensible the Installer will leave sensible data used to bootstrap the cluster in the S3 bucket.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- Allow the user to opt-out of deleting the S3 bucket created during the cluster bootstrap on AWS.
Why is this important?
- Some ROSA customers have SCP policies that prevent the deletion of any S3 bucket preventing ROSA adoption for these customers.
Scenarios
- As a user, I want to be able to instruct the Installer to keep the S3 bucket created during the cluster bootstrap so I can be compliant with my security policies where the account used to deploy OpenShift has not the privileges to remove any S3 bucket.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
User Story:
As a developer, I want to:
- Make the deletion of S3 buckets in AWS optional during bootstrap destroy
so that I can
- successfully install clusters in restricted environments.
Acceptance Criteria:
Description of criteria:
- A field is added in the install config for the users to set the S3 deletion to optional.
- Once the field is set, the bootstrap destroy stage does not delete the S3 buckets.
Engineering Details:
- Adding a field in the install config and piping it to terraform.
- If the S3 bucket creation is done in the cluster stage instead of bootstrap, the destroy bootstrap code does not delete the bucket.
- Might need to create two instances of S3 buckets, one in the bootstrap and one in the cluster stage and control which one is created using the new field in the install config.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Console Support of OpenShift Pipelines Migration to Tekton v1 API
Goals (aka. expected user outcomes)
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Description of problem
Pipeline API version is upgrading to v1 with Red Hat Pipeline operator 1.11.0 release.
https://tekton.dev/vault/pipelines-main/migrating-v1beta1-to-v1/
Acceptance Criteria
- Remove Resources tab from the pipeline details page
- Remove Resources section in pipeline builder form
Questions
Does this have to be backward compatible?
Will the features be equivalent? Will the UX / tests / documentation have to be updated?
Description
As a user,
Acceptance Criteria
- should add support for API version v1 for Pipeline as per the doc https://tekton.dev/vault/pipelines-main/migrating-v1beta1-to-v1/
- Update the tests and test data
Additional Details:
Description of problem:
When trying the old pipelines operator with the latest 4.14 build I couldn't see the Pipelines navigation items. The operator provides the Pipeline v1beta1, not v1.
Version-Release number of selected component (if applicable):
4.14 master only after https://github.com/openshift/console/pull/12729 was merged
How reproducible:
Always?
Steps to Reproduce:
- Setup a 4.14 nightly cluster
- Install Pipelines operator from https://artifacts.ospqa.com/builds/ (tested with 1.9.2/v4.13-2303061437)
Actual results:
- Pipelines navigation wasn't shown
Expected results:
- Pipelines plugin should work also with this Pipelines operator version?
Additional info:
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Complete during New status.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Problem:
As a developer of serverless functions, we don't provide any samples.
Goal:
Provide Serverless Function samples in the sample catalog. These would be utilizing the Builder Image capabilities.
Why is it important?
Use cases:
- <case>
Acceptance criteria:
- <criteria>
Dependencies (External/Internal):
- Serverless team would need to provide sample repo for serverless function
- Samples operator would need to be update
Design Artifacts:
Exploration:
Note:
- Need to define the API and confirm with other stakeholders - need to support a serverless func image stream "tag"
- Serverless team will need to provide updates to the existing Image Streams, as well as maintain the sample repositories which are referenced in the Image Streams.
- Need to understand the relationship between ImageStream and Image Stream Tag
- Should serverless function samples in the catalog have "builder image" tag? or should it be "serverless function"
Description
As an operator author, I want to provide additional samples that are tied to an operator version, not an OpenShift release. For that, I want to create a resource to add new samples to the web console.
Acceptance Criteria
- openshift/console-operator update so that new clusters have the new ConsoleSample CRD
- Add RBAC permissions (roles and rolebinding?) so that all users have access to ConsoleSample resources
Additional Details:
Description
As an operator author, I want to provide additional samples that are tied to an operator version, not an OpenShift release. For that, I want to create a resource to add new samples to the web console.
Acceptance Criteria
- Load all cluster-scoped ConsoleSamples resources and show them in the sample catalog
- Filter duplicates based on the localization annotations (see enhancement proposal)
- All localization labels are optional
- Fallback for the name annotation should be metadata.name
- Fallback for the language should be english/no annotation
- Create a utils function with some unit tests
- Ensure that the Samples Import also works with Serverless functions (func.yaml detection)
- Show the new VSCode and IntelliJ extension cards from the "Add Serverless function" when importing a Serverless function sample.
- Provide some ConsoleSample YAMLs in the PR description
Additional Details:
Feature Overview (aka. Goal Summary)
As Arm adoption grows OpenShift on Arm is a key strategic initiative for Red Hat. Key to success is the support of all key cloud providers adopting this technology. Google have announced support for Arm in their GCP offering and we need to support OpenShift in this configuration.
Goals (aka. expected user outcomes)
The ability to have OCP on Arm running in a GCP instance
Requirements (aka. Acceptance Criteria):
OCP on Arm running in a GCP instance
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Description:
Update 4.14 documentation to reflect new GCP support on ARM machines.
Updates:
- Add google instance types for ARM
- Add config parameters
- Supported installation platforms
- Release note
Acceptance criteria:
- Dev and QE ack
- PR is merged
Description:
In order to add instance types to the OCP documentation, there needs to be a .md file in the OpenShift installer repo that contains the 64-bit ARM machine types that have been texted and are supported on GCP.
Create a PR in the OpenShift installer repo that creates a new .md file that shows the supported instance types
Acceptance criteria:
- Dev and QE ack from ARM side
- Dev and QE ack from Installer side
- Approval from installer product manager
- PR is merged and ready to be used for OCP docs referencing
Feature Overview (aka. Goal Summary)
Azure File CSI supports both SMB and NFS protocol. Currently we only support SMB and there is a strong demand from IBM and individual customers to support NFS for posix compliance reasons.
Goals (aka. expected user outcomes)
Support Azure File CSI with NFS.
The Azure File operator will not automatically create a NFS storage class, we will document how to create one.
Requirements (aka. Acceptance Criteria):
There are some concerns on the way Azure File CSI deals with NFS. They don't respect the FSGroup policy supplied in the pod definition. This breaks kubernetes convention where a pod should be able to define its own FSGroup policy, instead Azure File CSI set a per driver policy that pods can't override.
We brought up this problem to MSFT but there is no fix planned on the driver, given the pressure from the field we are going to support NFS with a on root mismatch default and document this specific behavior in our documentation.
Use Cases (Optional):
As an OCP on Azure admin i want my user to be able to consume NFS based PVs through Azure File CSI.
As an OCP on Azure user i want to attach NFS based PVs to my pods.
As an ARO customer I want to consume NFS based PVs.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
Running two drivers, one for NFS and one for SMB to solve the FSGroup issue.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
This feature is candidate to be backported up to 4.12 if possible.
Documentation Considerations
Document that Azure File CSI NFS is supported, how to create a storage class as well as the FSGroup issue.
- Azure File NFS Supportability
- We currently have a CSI driver for Azure Files that supports SMB connectivity. In the interested of maintaining POSIX-compliance, supported NFS connectivity would be required.
- The goal would be to have supported parity with the current AWS offerings that use "AWS EFS Provisioner" to automatically provision NFS volumes.
It's been decided to support the driver as it is today (see spike STOR-992) knowing it violates fsGroupChangePolicy kubernetes standard where a pod is able to decide what FS group policy should be applied. Azure File with NFS applies a FS group policy at the driver level and pods cannot override it. We will keep the driver's default (on root mismatch) and document this non conventional behavior. Also, the Azure File CSI operator will not create a storage class for NFS, admins will need to create it manually this will be documented.
There is no need to specific development in the driver nor the operator, engineering will make sure we have a working CI.
1. Proposed title of this feature request
Enable privileged containers to view rootfs of other containers
2. What is the nature and description of the request?
The skip_mount_home=true field in the /etc/containers/storage.conf causes the mount propegation of container mounts to not be private, which allows privileged containers to access the rootfs of other containers. This is a fix for bug 2065283 (see comment #32 [2]).
This RFE is to enable that field by default in Openshift, as well as verify there are no performance regressions when applying it.
3. Why does the customer need this? (List the business requirements here)
Customer's use case:
Our agent runs as a daemonset in k8s clusters and monitors the node.
Running with mount propagation set to HostToContainer allows the agent to access any container file, also containers which start running after agent startup. With this settings, when a new container starts, a new mount is created and added to the host mount namespace and also to the agent container and by that the agent can access the container files
e.g. the agent is mounted to /host and can access to the filesystem of other container by path
/host/var/lib/containers/storage/overlay/xxxxxxxxxxxxxxxxxxxxxxxxxxxxx/merged/test_fileThis approach works in k8s clusters and OpenShift 3, but not in OpenShift 4. How can I make the agent pod to get noticed about any new mount which was created on the node and get access to it as well?
The workaround for that was provided in bug 2065283 (see comment #32 [2]).
4. List any affected packages or components.
CRI-O, Node, MCO.
Additional information in this Slack discussion [3].
[1] https://docs.openshift.com/container-platform/4.11/post_installation_configuration/machine-configuration-tasks.html#create-a-containerruntimeconfig_post-install-machine-configuration-tasks
[2] https://bugzilla.redhat.com/show_bug.cgi?id=2065283#c32
[3] https://coreos.slack.com/archives/CK1AE4ZCK/p1670491480185299
Epic Goal
- use the `skip_mount_home` parameter of /etc/containers/storage.conf to allow containers to see other container's rootfs
Why is this important?
Scenarios
- As an author to a node agent, I would like my pods to be able to inspect the rootfs of other containers to gain insight into their behavior.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
Currently, SCCs are part of the OpenShift API and are subject to modifications by customers. This leads to a constant stream of issues:
- Modifications of out-of-the-box SCCs cause core workloads to malfunction
- Addition of new higher priority SCCs may overrule existing pinned out-of-the-box SCCs during SCC admission and cause core workloads to malfunction
Goals (aka. expected user outcomes)
- Create a way to prevent SCC preemption and modifications of out-of-the-box SCCs
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Summary (PM+lead)
Currently, SCCs are part of the OpenShift API and are subject to modifications by customers. This leads to a constant stream of issues:
- Modifications of out-of-the-box SCCs may cause core workloads to malfunction
- Addition of new higher priority SCCs may overrule existing pinned out-of-the-box SCCs during SCC admission and cause core workloads to malfunction
We need to find and implement schemes to protect core workloads while retaining the API guarantee for modifications of SCCs (unfortunately).
Motivation (PM+lead)
Goals (lead)
Non-Goals (lead)
Deliverables
Proposal (lead)
User Stories (PM)
Dependencies (internal and external, lead)
Previous Work (lead)
Open questions (lead)
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
Users of the OpenShift Console leverage a streamlined, visual experience when discovering and installing OLM-managed operators in clusters that run on cloud providers with support for short-lived token authentication enabled. Users are intuitively becoming aware when this is the case and are put on the happy path to configure OLM-managed operators with the necessary information to support AWS STS.
Goals:
Customers do not need to re-learn how to enable AWS STS authentication support for each and every OLM-managed operator that supports it. The experience is standardized and repeatable so customers spend less time with initial configuration and more team implementing business value. The process is so easy that OpenShift is perceived as enabler for an increased security posture.
Requirements:
- based on
OCPBU-559andOCPBU-560, the installation and configuration experience for any OLM-managed operator using short-lived token authentication is streamlined using the OCP console in the form of a guided process that avoids misconfiguration or unexpected behavior of the operators in question - the OCP Console helps in detecting when the cluster itself is already using AWS STS for core functionality
- the OCP Console helps discover operators capable of AWS STS authentication and their IAM permission requirements
- the OCP Console drives the collection of the required information for AWS STS authentication at the right stages of the installation process and stops the process when the information is not provided
- the OCP Console implements this process with minimal differences across different cloud providers and is capable of adjusting the terminology depending on the cloud provider that the cluster is running on
Use Cases:
- High-level mockups found here: Operators & STS
- A cluster admin browses the OperatorHub catalog and looks at the details view of a particular operator, there they discover that the cluster is configured for AWS STS
- A cluster admin browsing the OperatorHub catalog content can filter for operators that support the AWS STS flow described in
OCPSTRAT-171 - A cluster admin reviewing the details of a particular operator in the OperatorHub view can discover that this operator supports AWS STS authentication
- A cluster admin installing a particular operator can get information about the AWS IAM permission requirements the operator has
- A cluster admin installing a particular operator is asked to provide AWS ARN that is required for AWS STS prior to the actual installation step and is prevented from continuing without this information
- A cluster admin reviewing an installed operators with support forAWS STS can discover the related CredentialRequest object that the operator created in an intuitive way (not generically via related objects that have an ownership reference or as part of the InstallPlan)
Out of Scope
- update handling and blocking in case of increased permission requirements in the next / new version of the operator
- more complex scenarios with multiple IAM roles/service principals resulting in multiple CredentialRequest objects used by a single operator
Background
The OpenShift Console today provides little to no support for configuring OLM-managed operators for short-lived token authentication. Users are generally unaware if their cluster runs on a cloud provider and is set up to use short-lived tokens for its core functionality and users are not aware which operators have support for that by implementing the respective flows defined in OCPBU-559 and OCPBU-560.
Customer Considerations
Customers may or may not be aware about short-lived token authentication support. They need to proper context and pointers to follow-up documentation to explain the general concept and the specific configuration flow the Console supports. It needs to become clear that the Console cannot 100% automate the overall process and some steps need to be run outside of the cluster/Console using Cloud-provider specific tooling.
This epic is tracking the console work needed for STS enablement. As well as documentation needed for enabling operator teams to use this new flow. This does not track Hypershift inclusion of CCO.
Plan is to backport to 4.12
install flow:
- User knows which operators do and don’t support STS on a ROSA STS cluster
- User installs Operator
- UI has an option to add a RoleARN the sub.config.env for the operator to add to the CredentialRequest during install
- Operator creates CredentialsRequest with AWS_ROLE_ARN
- Operator watches secret with special name (TBD) in the namespace
- CCO creates a secret in the pod namespace based on the CredentialsRequest created
- Operator extracts AWS_ROLE_ARN and AWS_WEB_IDENTITY_TOKEN from the secret
- Operator is able to configure the cloud provider SDK
As a user of the console, I would like to provide the required fields for tokenized auth at install time (wrapping and providing sane defaults for what I can do manually in the CLI).
The role ARN provided by the user should be added to the service account of the installed operator as an annotation.
Only manual subscription is supported in STS mode - the automatic option should be not be the default or should be grey'd out entirely
AC: Add input field to the operator install page, where user can provide the `roleARN` value. This value will be set on the operator's Subscription resource, when installing operator.
STS - Security Token Service
Cluster is in STS mode when:
- AWS
- credentialsMode in the `cloudcredential` resource is "Manual"
- serviceAccountIssuer is non empty
AC: Inform user on the Operator Hub item details that the cluster is in the STS mode
As a user of the console I would like to know which operators are safe to install (i.e. support tokenized auth or don't talk to the cloud provider).
AC: Add filter to the Operator Hub for filtering operators which have Short Lived Token Enabled
Feature Overview (aka. Goal Summary)
Upstream K8s deprecated PodSecurityPolicy and replaced it with a new built-in admission controller that enforces the Pod Security Standards (See here for the motivations for deprecation).] There is an OpenShift-specific dedicated pod admission system called Security Context Constraints. Our aim is to keep the Security Context Constraints pod admission system while also allowing users to have access to the Kubernetes Pod Security Admission.
With OpenShift 4.11, we are turned on the Pod Security Admission with global "privileged" enforcement. Additionally we set the "restricted" profile for warnings and audit. This configuration made it possible for users to opt-in their namespaces to Pod Security Admission with the per-namespace labels. We also introduced a new mechanism that automatically synchronizes the Pod Security Admission "warn" and "audit" labels.
With OpenShift 4.15, we intend to move the global configuration to enforce the "restricted" pod security profile globally. With this change, the label synchronization mechanism will also switch into a mode where it synchronizes the "enforce" Pod Security Admission label rather than the "audit" and "warn".
In OpenShift 4.14, we intend to deliver functionality in code that will help accelerate moving to PSA enforcement. This feature tracks those deliverables.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Complete during New status.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal*
Deliver tools and code that helps toward PSa enforcement
Why is this important? (mandatory)
What are the benefits to the customer or Red Hat? Does it improve security, performance, supportability, etc? Why is work a priority?
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
What
Don't enforce system defaults on a namespace's pod security labels, if it is managed by a user.
Why
If the managedFields (https://kubernetes.io/docs/reference/using-api/server-side-apply/#field-management) indicate that a user changed the pod security labels, we should not enforce system defaults.
A user might not be aware that the label syncer can be turned off and tries to manually change the state of the pod security profiles.
This fight between a user and the label syncer can cause violations.
< High-Level description of the feature ie: Executive Summary >
Goals
< Who benefits from this feature, and how? What is the difference between today’s current state and a world with this feature? >
Requirements
| Requirements | Notes | IS MVP |
< What are we making, for who, and why/what problem are we solving?>
Out of scope
<Defines what is not included in this story>
Dependencies
< Link or at least explain any known dependencies. >
Background, and strategic fit
< What does the person writing code, testing, documenting need to know? >
Assumptions
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Customer Considerations
< Are there specific customer environments that need to be considered (such as working with existing h/w and software)?>
Documentation Considerations
< What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)? >
What does success look like?
< Does this feature have doc impact? Possible values are: New Content, Updates to existing content, Release Note, or No Doc Impact?>
QE Contact
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Impact
< If the feature is ordered with other work, state the impact of this feature on the other work>
Related Architecture/Technical Documents
<links>
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
Goal
Additional improvements to segment, to enable the proper gathering of user telemetry and analysis
Problem
Currently, we have no accurate telemetry of the OpenShift Console usage across all fleet clusters. We should be able to utilize the auth and console telemetry to glean details which will allow us to get a picture of console usage by our customers.
There is no way to properly track specific pages
- Page titles are localized
- Details pages include the project name
Acceptance criteria
- User telemetry page title for all the resource details pages should be changed to resource · tab-name format. Product name should not be part of user telemetry page title
- Page title in UI for all the resource details pages should be changed to resource-name . resource . tab-name . Product-name format
- User telemetry page title should be non-translated value for tracking purpose
- Page title in UI should be translated value
Note:
- do we need to do anything to be GDPR compliant?
Description
Change page title for all resource details pages to {resource-name} · {resource} · {tab-name} · OKD
Acceptance Criteria
- Page title for all the resource details pages should be changed to {resource-name} · {resource} · {tab-name} · OKD format
- If details page does not have tabs, then {tab-name} can be just "Details"
- Page title should be translated value
Additional Details:
Need to check all the resource pages which have details page and change the title.
Description
Update page title to have non-translated title in {resource-name} · {resource} · {tab-name} · OKD format
All page titles of resource details page to be added as a non-translated value in {resource-name} · {resource} · {tab-name} · OKD format inside <title> component as attribute with name for ex, data-title-id and use this value in fireUrlChangeEvent to send it as title for telemetry page event. Refer spike https://issues.redhat.com/browse/ODC-7269 for more details
Acceptance Criteria
- Add data-title-id attribute for all the resource details page title component
- Use data-title-id as title value while sending URL change event to telemetry
- If data-title-id attribute value is not present in title use page title value
Additional Details:
Refer spike https://issues.redhat.com/browse/ODC-7269 for more details
labelKeyForNodeKind now returns translated value, before it used to return label key. So Change method name for labelKeyForNodeKind to getTitleForNodeKind
Feature Overview (aka. Goal Summary)
One of the steps in doing a disconnected environment install is to mirror the images to a designated system. This feature enhances oc-mirror to not handle the multi release payload, that is the payload that contains all the platform images (x86, Arm, IBM Power, IBM Z). This is a key feature towards supporting disconnected installs in a multi-architecture compute i.e. mixed architecture cluster environment.
Goals (aka. expected user outcomes)
Customers will be able to use oc-mirror to enable the multi payload in a disconnected environment.
Requirements (aka. Acceptance Criteria):
Allow oc-mirror to mirror the multi release payload
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- Add 'oc new-app' support for creating image streams with manifest list support
- Add 'oc new-build' support for creating image streams with manifest list support
Why is this important?
- oc commands that create image streams should work correctly on multi-arch clusters
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
ACCEPTANCE CRITERIA
- When creating a workload with 'oc new-app' that points to a manifest-listed image, users should be able to set an "--import-mode=" flag to 'PreserveOriginal' in order to preserve all architectures of the manifest list
- 'oc new-app --name <name> <manifestlist-image> --import-mode=PreserveOriginal' should not cause pods to fail due to being the incorrect architecture
- Ensure node scheduling happens properly on a heterogeneous cluster when running 'oc new-app' with '--import-mode=PreserveOriginal'
ImportMode api reference: https://github.com/openshift/api/blob/master/image/v1/types.go#L294
Original issue and discussion: https://coreos.slack.com/archives/CFFJUNP6C/p1664890804998069
ACCEPTANCE CRITERIA
- When creating a build with 'oc new-build' that points to a manifest-listed image, users should be able to set an "--import-mode=" flag to 'PreserveOriginal' to preserve all architectures of the manifest list and let any builder pods build from the manifestlisted image.
'oc new-build' should not cause pods to fail due to being the incorrect architectureEnsure node scheduling happens properly on a heterogeneous cluster when running 'oc new-build'
ImportMode api reference: https://github.com/openshift/api/blob/master/image/v1/types.go#L294
Feature Overview (aka. Goal Summary)
With this feature it will be possible to autoscale from zero, that is have machinesets that create new nodes without any existing current nodes, for use in a mixed architecture cluster configured with multi-architecture compute
Goals (aka. expected user outcomes)
To be able to create a machineset and scale from zero in a mixed architecture cluster environment
Requirements (aka. Acceptance Criteria):
Create a machineset and scale from zero in a mixed architecture cluster environment
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Filing a ticket based on this conversation here: https://github.com/openshift/enhancements/pull/1014#discussion_r798674314
Basically the tl;dr here is that we need a way to ensure that machinesets are properly advertising the architecture that the nodes will eventually have. This is needed so the autoscaler can predict the correct pool to scale up/down. This could be accomplished through user driven means like adding node arch labels to machinesets and if we have to do this automatically, we need to do some more research and figure out a way.
For autoscaling nodes in a multi-arch compute cluster, node architecture needs to be taken into account because such a cluster could potentially have nodes of upto 4 different architectures. Labels can be propagated today from the machineset to the node group, but they have to be injected manually.
This story explores whether the autoscaler can use cloud provider APIs to derive the architecture of an instance type and set the label accordingly rather than it needing to be a manual step.
For autoscaling nodes in a multi-arch compute cluster, node architecture needs to be taken into account because such a cluster could potentially have nodes of upto 4 different architectures. Labels can be propagated today from the machineset to the node group, but they have to be injected manually.
This story explores whether the autoscaler can use cloud provider APIs to derive the architecture of an instance type and set the label accordingly rather than it needing to be a manual step.
Feature Overview (aka. Goal Summary)
In 4.13 the vSphere CSI migration is in hybrid state. Greenfield 4.13 clusters have migration enabled by default while upgraded clusters have it turned off unless explicitely enabled by an administrator (referred as "opt-in").
This feature tracks the final work items required to enable vSphere CSI migration for all OCP clusters.
More information on the 4.13 vSphere CSI migration is available in the internal FAQ
Goals (aka. expected user outcomes)
Finalise vSphere CSI migration for all clusters ensuring that
- Greenfield 4.14 clusters have migration enabled
- Enable migration on clusters upgraded from 4.13 (for those that have it disable)
- Enable migration on cluster upgraded from 4.14.
- Disable the 4.13 featureset that allowed admins to opt in migration
Regardless of the clusters state (new or upgraded), which version it is upgrading from or status of CSI migration (enabled/disabled), they should all have CSI migration enabled.
This feature also includes upgrades checks in 4.12 & 4.13 to ensure that OCP is running on a recommended vSphere version (vSphere 7.0u3L+ or 8.0u2+)
Requirements (aka. Acceptance Criteria):
We should make sure that all issues that prevented us to enabled CSI migration by default in 4.13 are resolved. If some of these issues are fix in vSphere itself we might need to check for a certain vSphere build version before proceeding with the upgrade (from 4.12 or 4.13).
Use Cases (Optional):
- New 4.14 clusters
- Clusters upgraded from 4.13 with migration enabled
- Clusters upgraded from 4.13 with migration disabled
- Clusters upgraded from 4.12 (migration disabled)
Background
More information on the 4.13 vSphere CSI migration is available in the internal FAQ
Customer Considerations
Customers who upgraded from 4.12 will unlikely opt in migration so we will have quite a few clusters with migration enabled. Given we will enabled it in 4.14 for every clusters we need to be extra careful that all issues raised are fixed and set upgrade blockers if needed.
Documentation Considerations
Remove all migration opt-in occurences in the documentation.
Interoperability Considerations
We need to make sure that upgraded clusters are running on top of a vsphere version that contains all the required fixes.
Epic Goal*
Remove FeatureSet InTreeVSphereVolumes that we added in 4.13.
Why is this important? (mandatory)
We assume that the CSI Migration will be GA and locked to default in Kubernetes 1.27 / OCP 4.14. Therefore the FeatureSet must be removed.
Scenarios (mandatory)
See https://issues.redhat.com/browse/STOR-1265 for upgrade from 4.13 to 4.14
Dependencies (internal and external) (mandatory)
Same as STOR-1265, just the other way around ("a big revert")
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Description of problem:
The vsphereStorageDriver is deprecated and we should allow cluster admins to remove that field from the Storage object in 4.14. This is the validation rule that prevents removing vsphereStorageDriver: https://github.com/openshift/api/blob/0eef84f63102e9d2dfdb489b18fa22676f2bd0c4/operator/v1/types_storage.go#L42 This was originally put in place to ensure that CSI Migration is not disabled again once it has been enabled. However, in 4.14 there is no way to disable migration, and there is an explicit rule to prevent setting LegacyDeprecatedInTreeDriver. So it should be safe to allow removing the vsphereStorageDriver field in 4.14, as this will not disable migration, and the field will eventually be removed from the API in a future release.
Version-Release number of selected component (if applicable):
4.14.0
How reproducible:
Steps to Reproduce:
1. Set vsphereStorageDriver in the Storage object 2. Try to remove vsphereStorageDriver
Actual results:
* spec: Invalid value: "object": VSphereStorageDriver is required once set
Expected results:
should be allowed
Additional info:
Feature Overview (aka. Goal Summary)
By moving MCO certificate management out of MachineConfigs, certificate rotation can happen any time, even when pools are paused and would generate no drain or reboot.
Goals (aka. expected user outcomes)
Eliminate problems causes by certificate rotations being blocked by paused pools. Keep certificates up-to-date without disruption to workloads.
Requirements (aka. Acceptance Criteria):
- MCD reads certificates from our "controllerconfig" directly.
Interoperability Considerations
Windows MCO has been updated to work with this path.
Feature Overview (aka. Goal Summary)
Having additional MCO metrics is helpful to customers who want to closely monitor the state of their Machines and MachineConfigPools.
Requirements (aka. Acceptance Criteria):
Add for each MCP:
- Paused
- Updated
- Updating
- Degraded
- Machinecount
- ReadyMachineCount
- UpdatedMachineCount
- DegradedMachineCount
Creating this to version scope the improvements merged into 4.14. Since those changes were in a story, they need an epic.
Customer like to have in Prometheus some metrics of MachineConfigOperator. For each MCP:
- Paused
- Updated
- Updating
- Degraded
- Machinecount
- ReadyMachineCount
- UpdatedMachineCount
- DegradedMachineCount
Why does the customer need this? (List the business requirements here)
These metrics would be really important, as it could show any MachineConfig action (updating, degraded, ...), which could also even trigger an alarm with a PrometheusRule. Having a dashboard of MachineConfig would be also really useful.
Note: Replace text in red with details of your feature request.
Feature Overview
Extend the Workload Partitioning feature to support multi-node clusters.
Goals
Customers running RAN workloads on C-RAN Hubs (i.e. multi-node clusters) that want to maximize the cores available to the workloads (DU) should be able to utilize WP to isolate CP processes to reserved cores.
Requirements
A list of specific needs or objectives that a Feature must deliver to satisfy the Feature. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| requirement | Notes | isMvp? |
Describe Use Cases (if needed)
< How will the user interact with this feature? >
< Which users will use this and when will they use it? >
< Is this feature used as part of current user interface? >
Out of Scope
Background, and strategic fit
< What does the person writing code, testing, documenting need to know? >
Assumptions
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Customer Considerations
< Are there specific customer environments that need to be considered (such as working with existing h/w and software)?>
< Are there Upgrade considerations that customers need to account for or that the feature should address on behalf of the customer?>
<Does the Feature introduce data that could be gathered and used for Insights purposes?>
Documentation Considerations
< What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)? >
< What does success look like?>
< Does this feature have doc impact? Possible values are: New Content, Updates to existing content, Release Note, or No Doc Impact>
< If unsure and no Technical Writer is available, please contact Content Strategy. If yes, complete the following.>
- <What concepts do customers need to understand to be successful in [action]?>
- <How do we expect customers will use the feature? For what purpose(s)?>
- <What reference material might a customer want/need to complete [action]?>
- <Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available. >
- <What is the doc impact (New Content, Updates to existing content, or Release Note)?>
Interoperability Considerations
< Which other products and versions in our portfolio does this feature impact?>
< What interoperability test scenarios should be factored by the layered product(s)?>
Questions
| Question | Outcome |
Write a test to execute a known management pods and create a management pod to verify that it adheres to the CPU Affinity and CPU Shares
Ex:
pgrep kube-apiserver | while read i; do taskset -cp $i; done
DaemonSet and Deployment resource checks seem to flake, need to be resolved.
Check on FeatureSet Techpreview no longer needed on the installer, removing the check from the code.
Make validation tests run on all platforms by removing skips.
The original implementation of workload partitioning tried to leverage default behavior for CRIO to allow full use of CPU Sets when no Performance Profile is supplied by the user while still being a CPU partitioned cluster. This works fine for CPU affinity however because we don't supply a config and allow the default behavior to kick in, CRIO does not alter the CPU share and gives all pods 2 CPU Share value.
We need to supply a config for CRIO with an empty string for CPU Set to support both CPU share and CPU affinity behavior when NO performance profile is supplied, so that the `resource.requests` which get altered to CPU Share, are correctly being applied in a default state.
Note, this is not an issue with CPU affinity, that still behaves as expected and when a performance profile is supplied things work as intended as well. The CPU share mismatch is the only issue being identified here.
Create generic validation tests in Origin and Release repo to check that a cluster is correctly configured. E2E tests running in a cpu partitioned cluster should run successfully.