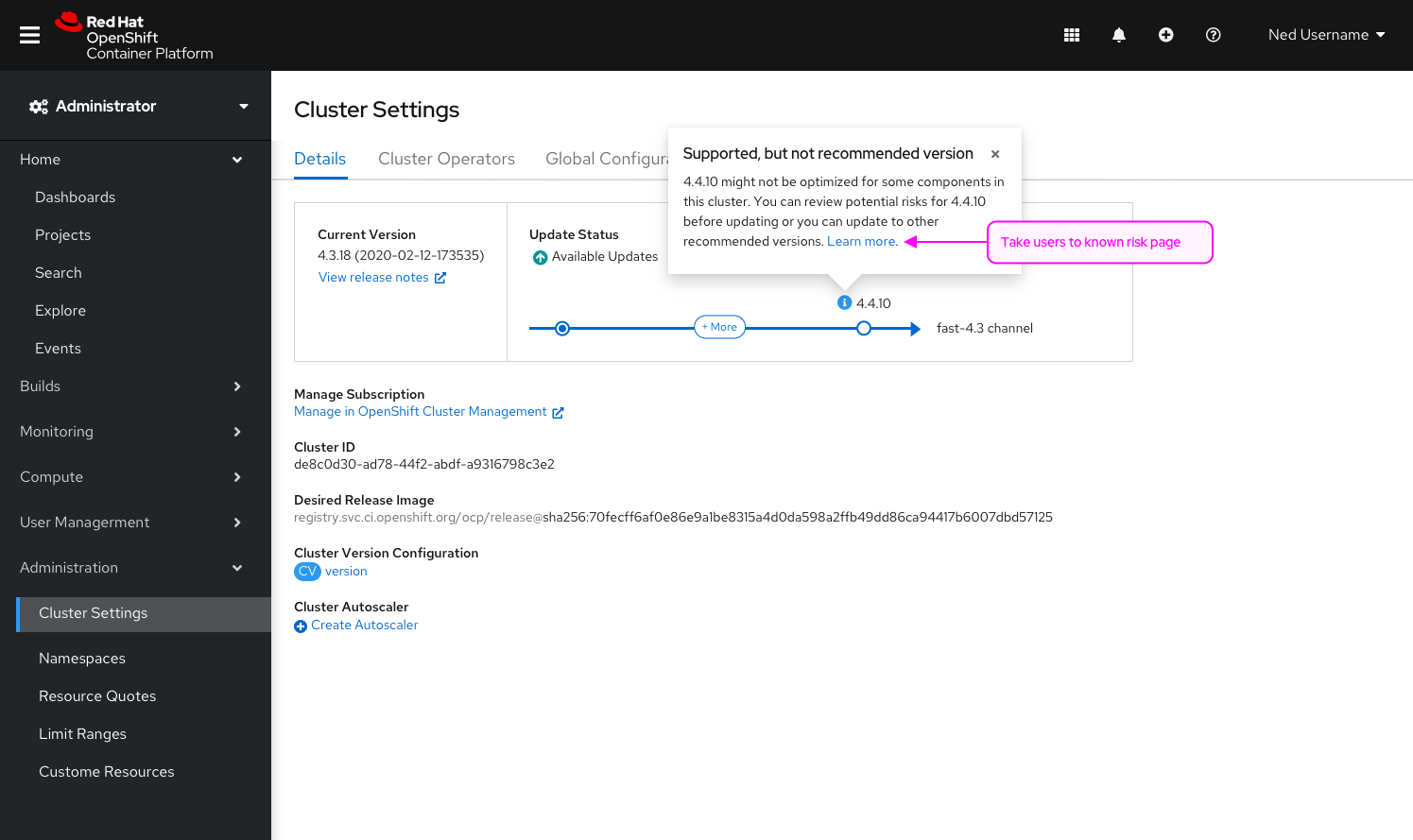
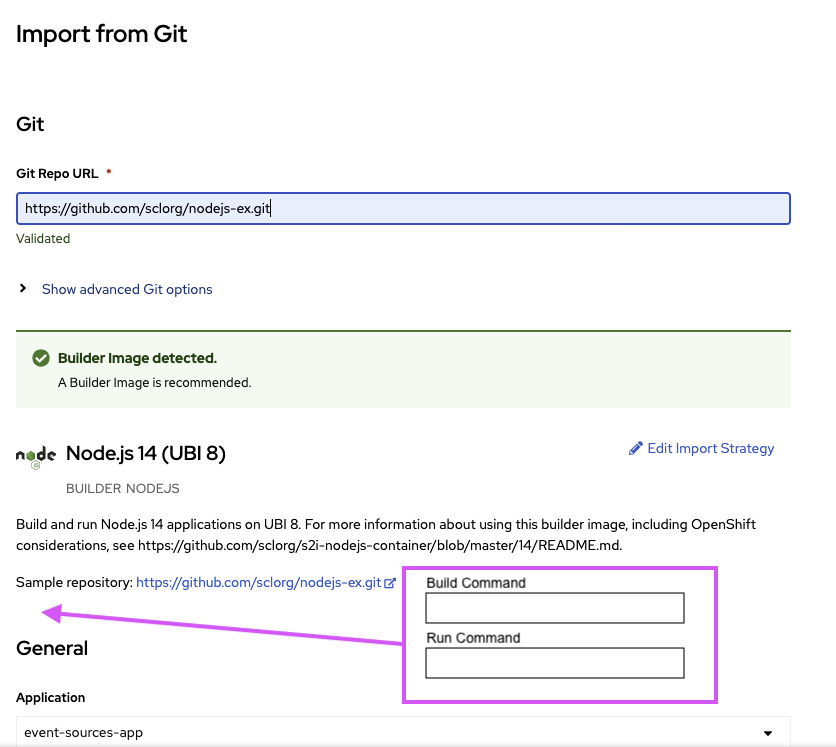
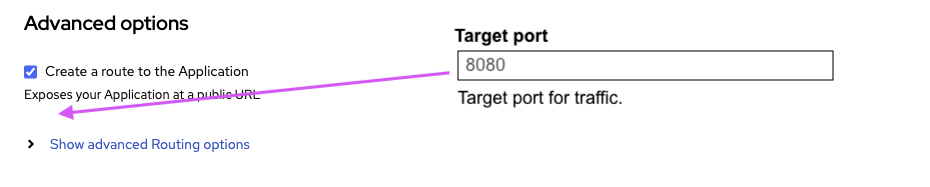
Complete Features
These features were completed when this image was assembled
Feature Overview
Insights Advisor for OpenShift is integrated within OpenShift Cluster Manager. This has some limitations for adding new features and also for sharing codebase between RHEL Advisor and OCM Insights Advisor tab. Insights Advisor for OpenShift lacks certain features from the RHEL UI, the codebase is not 1:1 clone.
As a customer of Insights I will have same/very similar user experience with Insights for OpenShift and Insights for RHEL. The workflows will share the main concepts, the UI elements will be same and features introduced to Advisor will be automatically considered for both all supported platforms.
As OpenShift users I will still see integrations of Insights Advisor within OpenShift Cluster Manager that shows aggregated information for customer account and single cluster view on Advisor data. These integration will point to new Insights Advisor for OpenShift app that will be tightly integrated into OpenShift Cluster Manager.
- Note: The application will be reusing the codebase but will run as a separate app for OpenShift. THere's no intent to merge RHEL and OpenShift workflows into a single app.
Goals
- Q2CY21: Explore possibility to unify codebase between RHEL Advisor and OCM Insights Advisor tab. Identify architecture misalignments, create UI mockups to merge the two existing UIs.
- Q3CY21: Integrate OpenShift into Advisor codebase, standup the Insights Advisor for OpenShift application and change integration in OpenShift Cluster manager to point at the new app
- Q4CY21: Deliver missing screen of Insights Advisor for OpenShift (Systems and Recommendations views)
Requirements
- UX overview of UI elements in both UIs - Marie Doruskova
- Architecture overview/misalignments for both UIs - Jan Zeleny [~fjansen]
Benefits
- Feature parity between RHEL and OpenShift
- Adopting new features developed by RHEL Advisor team quicker
- Smaller maintenance cost
Questions to answer...
- Possible deviations between OpenShift and RHEL
- Remediation workflow different between OpenShift and RHEL
Out of Scope
- Single app that combines RHEL hosts and OpenShift clusters. Goal is still to differentiate between platforms and offer view only for a single platform.
- Direct/Supervised remediations and integration of remediations with Advanced Cluster Manager (as a Service)
Background, and strategic fit
- Insights Advisor for OpenShift follows the goal to introduce multiple applications that add value for OpenShift customers under the Insights brand. The current UI and integration of Advisor into OpenShift cluster manager doesn't follow pattern that other Insights for OpenShift applications can/will follow.
Documentation Considerations
- OCM documentation is impacted, existing workflows described in OCM documentation will persist. The placement of the application within OCM will be different.
OCP WebConsole, in the main dashboard, has an Insights Advisor widget, which has been redirecting users to OCM. Due to the Insights Advisor tab decommission in OCM, the links should point to Advisor instead.
4.10 code freeze = 28 January (marking the task as urgent)
Problem:
Certain Insights Advisor features differentiate between RHEL and OCP advisor
Goal:
Address top priority UI misalignments between RHEL and OCP advisor. Address UI features dropped from Insights ADvisor for OCP GA.
Scope:
Specific tasks and priority of them tracked in https://issues.redhat.com/browse/CCXDEV-7432
This contains all the Insights Advisor widget deliverables for the OCP release 4.11.
Scope
It covers only minor bug fixes and improvements:
- better error handling during internal outages in data processing
- add "last refresh" timestamp in the Advisor widget
Show the error message (mocked in CCXDEV-5868) if the Prometheus metrics `cluster_operator_conditions{name="insights"}` contain two true conditions: UploadDegraded and Degraded at the same time. This state occurs if there was an IO archive upload error = problems with the pipeline.
Expected for 4.11 OCP release.
Scenario: Check if the Insights Advisor widget in the OCP WebConsole UI shows the time of the last data analysis Given: OCP WebConsole UI and the cluster dashboard is accessible And: CCX external data pipeline is in a working state And: administrator A1 has access to his cluster's dashboard And: Insights Operator for this cluster is sending archives When: administrator A1 clicks on the Insights Advisor widget Then: the results of the last analysis are showed in the Insights Advisor widget And: the time of the last analysis is shown in the Insights Advisor widget
Acceptance criteria:
- The time of the last analysis is shown in the Insights Advisor widget for the scenario above
- The way it is presented is defined within the scope of https://issues.redhat.com/browse/CCXDEV-5869 (mockup task)
- The source of this timestamp must be a result of running the Prometheus metric (last archive upload time):
max_over_time(timestamp(changes(insightsclient_request_send_total\{status_code="202"}[1m]) > 0)[24h:1m])
Epic Goal
- Allow admin user to create new alerting rules, targeting metrics in any namespace
- Allow cloning of existing rules to simplify rule creation
- Allow creation of silences for existing alert rules
Why is this important?
- Currently, any platform-related metrics (exposed in a openshift-, kube- and default namespace) cannot be used to form a new alerting rule. That makes it very difficult for administrators to enrich our out of the box experience for the OpenShift Container Platform with new rules that may be specific to their environments.
- Additionally, we had requests from customer to allow modifications of our existing, out of the box alerting rules (for instance tweaking the alert expression or changing the severity label). Unfortunately, that is not easy since most rules come from several open source projects, or other OpenShift components, and any modifications would make a seamless upgrade not really seamless anymore. Imagine K8s changes metrics again (see 1.14) and we have to update our rules. We would not know what modifications have been done (even just the threshold might be difficult if upstream changes that as well) and we would not be able to upgrade these rules.
Scenarios
- I'd like to modify the query expression of an existing rule (because the threshold value doesn't match with my environment).
Cloning the existing rule should end up with a new rule in the same namespace.
Modifications can now be done to the new rule.
(Optional) You can silence the existing rule.
- I'd like to create a new rule based on a metric only available to an openshift-* namespace
Create a new PrometheusRule object inside the namespace that includes the metrics you need to form the alerting rule.
- I'd like to update the label of an existing rule.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Ability to distinguish between rules deployed by us (CMO) and user created rules
Dependencies (internal and external)
Previous Work (Optional):
Open questions::
- Distinguish between operator-created rules and user-created rules
Currently no such mechanism exists. This will need to be added to prometheus-operator or cluster-monitoring-operator.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
CMO should reconcile the platform Prometheus configuration with the alert-relabel-config resources.
DoD
- Alerts changed via alert-relabel-configs are evaluated by the Platform monitoring stack.
- Product alerts which are overriden aren't sent to Alertmanager
CMO should reconcile the platform Prometheus configuration with the AlertingRule resources.
DoD
- Alerts added via AlertingRule resources are evaluated by the Platform monitoring stack.
Managing PVs at scale for a fleet creates difficulties where "one size does not fit all". The ability for SRE to deploy prometheus with PVs and have retention based an on a desired size would enable easier management of these volumes across the fleet.
The prometheus-operator exposes retentionSize.
| Field | Description |
|---|---|
| retentionSize | Maximum amount of disk space used by blocks. Supported units: B, KB, MB, GB, TB, PB, EB. Ex: 512MB. |
This is a feature request to enable this configuration option via CMO cluster-monitoring-config ConfigMap.
Epic Goal
- Cluster admins want to configure the retention size for their metrics.
Why is this important?
- While it is possible to define how long metrics should be retained on disk, it's not possible to tell the cluster monitoring operator how much data it should keep. For OSD/ROSA in particular, it would facilitate the management of the fleet if the retention size could be configured based on the persistent volume size because it would avoid issues with the storage getting full and monitoring being down when too many metrics are produced.
Scenarios
- As a cluster admin, I want to define the maximum amount of data to be retained on the persistent volume.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- The cluster-monitoring-config config and the user-workload-monitoring-config configmap allow to configure the retention size for
- Prometheus (Platform and UWM)
- Thanos Ruler (to be confirmed)
- Proper validation is in place preventing bad user inputs from breaking the stack.
Dependencies (internal and external)
- Thanos ruler doesn't support retention size (only retention time).
Previous Work (Optional):
- None
Open questions::
- None
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Problem Alignment
The Problem
Today, all configuration for setting individual, for example, routing configuration is done via a single configuration file that only admins have access to. If an environment uses multiple tenants and each tenant, for example, has different systems that they are using to notify teams in case of an issue, then someone needs to file a request w/ an admin to add the required settings.
That can be bothersome for individual teams, since requests like that usually disappear in the backlog of an administrator. At the same time, administrators might get tons of requests that they have to look at and prioritize, which takes them away from more crucial work.
We would like to introduce a more self service approach whereas individual teams can create their own configuration for their needs w/o the administrators involvement.
Last but not least, since Monitoring is deployed as a Core service of OpenShift there are multiple restrictions that the SRE team has to apply to all OSD and ROSA clusters. One restriction is the ability for customers to use the central Alertmanager that is owned and managed by the SRE team. They can't give access to the central managed secret due to security concerns so that users can add their own routing information.
High-Level Approach
Provide a new API (based on the Operator CRD approach) as part of the Prometheus Operator that allows creating a subset of the Alertmanager configuration without touching the central Alertmanager configuration file.
Please note that we do not plan to support additional individual webhooks with this work. Customers will need to deploy their own version of the third party webhooks.
Goal & Success
- Allow users to deploy individual configurations that allow setting up Alertmanager for their needs without an administrator.
Solution Alignment
Key Capabilities
- As an OpenShift administrator, I want to control who can CRUD individual configuration so that I can make sure that any unknown third person can touch the central Alertmanager instance shipped within OpenShift Monitoring.
- As a team owner, I want to deploy a routing configuration to push notifications for alerts to my system of choice.
Key Flows
Team A wants to send all their important notifications to a specific Slack channel.
- Administrator gives permission to Team A to allow creating a new configuration CR in their individual namespace.
- Team A creates a new configuration CR.
- Team A configures what alerts should go into their Slack channel.
- Open Questions & Key Decisions (optional)
- Do we want to improve anything inside the developer console to allow configuration?
As described in https://github.com/openshift/enhancements/blob/ba3dc219eecc7799f8216e1d0234fd846522e88f/enhancements/monitoring/multi-tenant-alerting.md#distinction-between-platform-and-user-alerts, cluster admins want to distinguish platform alerts from user alerts. For this purpose, CMO should provision an external label (openshift_io_alert_source="platform") on prometheus-k8s instances.
Epic Goal
- Allow users to manage Alertmanager for user-defined alerts and have the feature being fully supported.
Why is this important?
- Users want to configure alert notifications without admin intervention.
- The feature is currently Tech Preview, it should be generally available to benefit a bigger audience.
Scenarios
- As a cluster admin, I can deploy an Alertmanager service dedicated for user-defined alerts (e.g. separated from the existing Alertmanager already used for platform alerts).
- As an application developer, I can silence alerts from the OCP console.
- As an application developer, I'm not allowed to configure invalid AlertmanagerConfig objects.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- The AlertmanagerConfig CRD is v1beta1
- The validating webhook service checking AlertmanagerConfig resources is highly-available.
Dependencies (internal and external)
- Prometheus operator upstream should migrate the AlertmanagerConfig CRD from v1alpha1 to v1beta1
- Console enhancements likely to be involved (see below).
Previous Work (Optional):
- Part of the feature is available as Tech Preview (
MON-880).
Open questions:
- Coordination with the console team to support the Alertmanager service dedicated for user-defined alerts.
- Migration steps for users that are already using the v1alpha1 CRD.
Done Checklist
* CI - CI is running, tests are automated and merged.
* Release Enablement <link to Feature Enablement Presentation>
* DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
* DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
* DEV - Downstream build attached to advisory: <link to errata>
* QE - Test plans in Polarion: <link or reference to Polarion>
* QE - Automated tests merged: <link or reference to automated tests>
* DOC - Downstream documentation merged: <link to meaningful PR>
Now that upstream supports AlertmanagerConfig v1beta1 (see MON-2290 and https://github.com/prometheus-operator/prometheus-operator/pull/4709), it should be deployed by CMO.
DoD:
- Kubernetes API exposes and supports the v1beta1 version for AlertmanagerConfig CRD (in addition to v1alpha1).
- Users can manage AlertmanagerConfig v1beta1 objects seamlessly.
- AlertmanagerConfig v1beta1 objects are reconciled in the generated Alertmanager configuration.
Epic Goal
- The goal is to support metrics federation for user-defined monitoring via the /federate Prometheus endpoint (both from within and outside of the cluster).
Why is this important?
- It is already possible to configure remote write for user-defined monitoring to push metrics outside of the cluster but in some cases, the network flow can only go from the outside to the cluster and not the opposite. This makes it impossible to leverage remote write.
- It is already possible to use the /federate endpoint for the platform Prometheus (via the internal service or via the OpenShift route) so not supporting for UWM doesn't provide a consistent experience.
- If we don't expose the /federate endpoint for the UWM Prometheus, users would have no supported way to store and query application metrics from a central location.
Scenarios
- As a cluster admin, I want to federate user-defined metrics using the Prometheus /federate endpoint.
- As a cluster admin, I want that the /federate endpoint to UWM is accessible via an OpenShift route.
- As a cluster admin, I want that the access to the /federate endpoint to UWM requires authentication (with bearer token only) & authorization (the required permissions should match the permissions on the /federate endpoint of the Platform Prometheus).
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Documentation - information about the recommendations and limitations/caveats of the federation approach.
- User can federate user-defined metrics from within the cluster
- User can federate user-defined metrics from the outside via the OpenShift route.
Dependencies (internal and external)
- None
Previous Work (Optional):
- None
Open questions:
- None
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
DoD
- User can federate UWM metrics from outside of the cluster via the OpenShift route.
- E2E test added to the CMO test suite.
DoD
- User can federate UWM metrics within the cluster from the prometheus-user-workload.openshift-user-workload-monitoring.svc:9092 service
- The service requires authentication via bearer token and authorization (same permissions as for federating platform metrics)
Copy/paste from [_https://github.com/openshift-cs/managed-openshift/issues/60_]
Which service is this feature request for?
OpenShift Dedicated and Red Hat OpenShift Service on AWS
What are you trying to do?
Allow ROSA/OSD to integrate with AWS Managed Prometheus.
Describe the solution you'd like
Remote-write of metrics is supported in OpenShift but it does not work with AWS Managed Prometheus since AWS Managed Prometheus requires AWS SigV4 auth.
- Note that Prometheus supports AWS SigV4 since v2.26 and OpenShift 4.9 uses v2.29.
Describe alternatives you've considered
There is the workaround to use the "AWS SigV4 Proxy" but I'd think this is not properly supported by RH.
https://mobb.ninja/docs/rosa/cluster-metrics-to-aws-prometheus/
Additional context
The customer wants to use an open and portable solution to centralize metrics storage and analysis. If they also deploy to other clouds, they don't want to have to re-configure. Since most clouds offer a Prometheus service (or it's easy to self-manage Prometheus), app migration should be simplified.
Epic Goal
The cluster monitoring operator should allow OpenShift customers to configure remote write with all authentication methods supported by upstream Prometheus.
We will extend CMO's configuration API to support the following authentications with remote write:
- Sigv4
- Authorization
- OAuth2
Why is this important?
Customers want to send metrics to AWS Managed Prometheus that require sigv4 authentication (see https://docs.aws.amazon.com/prometheus/latest/userguide/AMP-secure-metric-ingestion.html#AMP-secure-auth).
Scenarios
- As a cluster admin, I want to forward platform/user metrics to remote write systems requiring Sigv4 authentication.
- As a cluster admin, I want to forward platform/user metrics to remote write systems requiring OAuth2 authentication.
- As a cluster admin, I want to forward platform/user metrics to remote write systems requiring custom Authorization header for authentication (e.g. API key).
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- It is possible for a cluster admin to configure any authentication method that is supported by Prometheus upstream for remote write (both platform and user-defined metrics):
-
- Sigv4
- Authorization
- OAuth2
Dependencies (internal and external)
- In theory none because everything is already supported by the Prometheus operator upstream. We may discover bugs in the upstream implementation though that may require upstream involvement.
Previous Work
- After CMO started exposing the RemoteWrite specification in
MON-1069, additional authentication options where added to prometheus and prometheus-operator but CMO didn't catch up on these.
Open Questions
- None
Prometheus and Prometheus operator already support sigv4 authentication for remote write. This should be possible to configure the same in the CMO configuration:
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://remote-write.endpoint"
sigv4:
accessKey:
name: aws-credentialss
key: access
secretKey:
name: aws-credentials
key: secret
profile: "SomeProfile"
roleArn: "SomeRoleArn"
DoD:
- Ability to configure sigv4 authentication for remote write in the openshift-monitoring/cluster-monitoring-config configmap
- Ability to configure sigv4 authentication for remote write in the openshift-user-workload-monitoring/user-workload-monitoring-config configmap
Prometheus and Prometheus operator already support custom Authorization for remote write. This should be possible to configure the same in the CMO configuration:
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://remote-write.endpoint"
Authorization:
type: Bearer
credentials:
name: credentials
key: token
DoD:
- Ability to configure custom Authorization for remote write in the openshift-monitoring/cluster-monitoring-config configmap
- Ability to configure custom Authorization for remote write in the openshift-user-workload-monitoring/user-workload-monitoring-config configmap
Description
As WMCO user, I want to make sure containerd logging information has been updated in documents and scripts.
Acceptance Criteria
- update must-gather to collect containerd logs
- Internal/Customer Documents and log collecting scripts must have containerd specific information (ex: location of logs).
Summary (PM+lead)
Configure audit logging to capture login, logout and login failure details
Motivation (PM+lead)
TODO(PM): update this
Customer who needs login, logout and login failure details inside the openshift container platform.
I have checked for this on my test cluster but the audit logs do not contain any user name specifying login or logout details. For successful logins or logout, on CLI and openshift console as well we can see 'Login successful' or 'Invalid credentials'.
Expected results: Login, logout and login failures should be captured in audit logging.
Goals (lead)
- Login,
logoutand login failures should be captured in audit logs
Non-Goals (lead)
- Don't attempt to log login failures in the IdP login flow that goes beyond timeout, if it the information is not available in explicit oauth-server requests (e.g. github password login error).
- Logout does not involve oauth-server (but is a simple API object deletion in oauth-apiserver). Hence, the audit log discussed here won't include logout.
Deliverables
- Changes to oauth-server to log into /varLog/oauth-server/audit.log on the master node.
- Documentation
Proposal (lead)
The apiserver pods today have ´/var/log/<kube|oauth|openshift>-apiserver` mounted from the host and create audit files there using the upstream audit event format (JSON lines following https://github.com/kubernetes/apiserver/blob/92392ef22153d75b3645b0ae339f89c12767fb52/pkg/apis/audit/v1/types.go#L72). These events are apiserver specific, but as oauth authentication flow events are also requests, we can use the apiserver event format to log logins, login failures and logouts. Hence, we propose to make oauth-server to create /var/log/oauth-server/audit.log files on the master nodes using that format.
When the login flow does not finish within a certain time (e.g. 10min), we can artificially create an event to show a login failure in the audit logs.
User Stories (PM)
Dependencies (internal and external, lead)
Previous Work (lead)
Open questions (lead)
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Right now there's no way to generate audit logs from this.
🏆 What
Let the Cluster Authentication Operator deliver the policy to OAuthServer.
💖 Why
In order to know if authn events should be logged, OAuthServer needs to be aware of it.
🗒 Notes
* Stanislav LázničkaCreate an observer to deliver the audit policy to the oauth server
Make the authentication-operator react to the new audit field in the oauth.config/cluster object. Write an observer watching this field, such an observer will translate the top-level configuration into oauth-server config and add it to the rest of the observed config.
Right now there's no way to generate audit logs from this.
OCP/Telco Definition of Done
Feature Template descriptions and documentation.
Feature Overview.
Early customer feedback is that they see SNO as a great solution covering smaller footprint deployment, but are wondering what is the evolution story OpenShift is going to provide where more capacity or high availability are needed in the future.
While migration tooling (moving workload/config to new cluster) could be a mid-term solution, customer desire is not to include extra hardware to be involved in this process.
For Telecommunications Providers, at the Far Edge they intend to start small and then grow. Many of these operators will start with a SNO-based DU deployment as an initial investment, but as DUs evolve, different segments of the radio spectrum are added, various radio hardware is provisioned and features delivered to the Far Edge, the Telecommunication Providers desire the ability for their Far Edge deployments to scale up from 1 node to 2 nodes to n nodes. On the opposite side of the spectrum from SNO is MMIMO where there is a robust cluster and workloads use HPA.
Goals
- Provide the capability to expand a single replica control plane topology to host more workloads capacity - add worker
- Provide the capability to expand a single replica control plane to be a highly available control plane
- To satisfy MMIMO Telecommunications providers will want the ability to scale a SNO to a multi-node cluster that can support HPA.
- Telecommunications providers do not want workload (DU specifically) downtime when migrating from SNO to a multi-node cluster.
- Telecommunications providers wish to be able to scale from one to two or more nodes to support a variety of radio hardware.
- Support CP scaling (CP HA) for 2 node cluster, 3 node cluster and n node cluster. As the number of nodes in the cluster increases so does the failure domain of the cluster. The cluster is now supporting more cell sectors and therefore has more of a need for HA and resiliency including the cluster CP.
Requirements
- TBD
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Epic Goal
- Documented and supported flow for adding 1, 2, 3 or more workers to a Single Node OpenShift (SNO) deployment without requiring cluster downtime and the understanding that this action will not make the cluster itself highly available.
Why is this important?
- Telecommunications and Edge scenarios where HA is handled via failover to another site but single site capacity may vary or need to be expanded over time.
- Similar scenarios exist for some ISV vendors where OpenShift is an implementation detail of how they deliver their solution on top of another platform (e.g. VMware).
Scenarios
- Adding a worker to a single node openshift cluster.
- Adding a second worker to a single node openshift cluster.
- Adding a third worker to a single node openshift cluster.
- Removing a worker node from a single node openshift cluster that has had 1 or more workers added.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Customer facing documentation of the add worker flow for SNO.
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- Presumably there is a scale limit on how many workers could be added to an SNO control plane, and it is lower than the limit for a "normal" 3 node control plane. It is not anticipated that this limit will be established in this epic. Intent is to focus on small scale sites where adding 1-3 worker nodes would be beneficial.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This is a ticket meant to track all the all the OCP PRs that are involved in the implementation of the SNO + workers enhancement
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Rebase OpenShift components to k8s v1.24
Why is this important?
- Rebasing ensures components work with the upcoming release of Kubernetes
- Address tech debt related to upstream deprecations and removals.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- k8s 1.24 release
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Rebase openshift/builder to k8s 1.24
Feature Overview
- As an infrastructure owner, I want a repeatable method to quickly deploy the initial OpenShift cluster.
- As an infrastructure owner, I want to install the first (management, hub, “cluster 0”) cluster to manage other (standalone, hub, spoke, hub of hubs) clusters.
Goals
- Enable customers and partners to successfully deploy a single “first” cluster in disconnected, on-premises settings
Requirements
4.11 MVP Requirements
- Customers and partners needs to be able to download the installer
- Enable customers and partners to deploy a single “first” cluster (cluster 0) using single node, compact, or highly available topologies in disconnected, on-premises settings
- Installer must support advanced network settings such as static IP assignments, VLANs and NIC bonding for on-premises metal use cases, as well as DHCP and PXE provisioning environments.
- Installer needs to support automation, including integration with third-party deployment tools, as well as user-driven deployments.
- In the MVP automation has higher priority than interactive, user-driven deployments.
- For bare metal deployments, we cannot assume that users will provide us the credentials to manage hosts via their BMCs.
- Installer should prioritize support for platforms None, baremetal, and VMware.
- The installer will focus on a single version of OpenShift, and a different build artifact will be produced for each different version.
- The installer must not depend on a connected registry; however, the installer can optionally use a previously mirrored registry within the disconnected environment.
Use Cases
- As a Telco partner engineer (Site Engineer, Specialist, Field Engineer), I want to deploy an OpenShift cluster in production with limited or no additional hardware and don’t intend to deploy more OpenShift clusters [Isolated edge experience].
- As a Enterprise infrastructure owner, I want to manage the lifecycle of multiple clusters in 1 or more sites by first installing the first (management, hub, “cluster 0”) cluster to manage other (standalone, hub, spoke, hub of hubs) clusters [Cluster before your cluster].
- As a Partner, I want to package OpenShift for large scale and/or distributed topology with my own software and/or hardware solution.
- As a large enterprise customer or Service Provider, I want to install a “HyperShift Tugboat” OpenShift cluster in order to offer a hosted OpenShift control plane at scale to my consumers (DevOps Engineers, tenants) that allows for fleet-level provisioning for low CAPEX and OPEX, much like AKS or GKE [Hypershift].
- As a new, novice to intermediate user (Enterprise Admin/Consumer, Telco Partner integrator, RH Solution Architect), I want to quickly deploy a small OpenShift cluster for Poc/Demo/Research purposes.
Questions to answer…
Out of Scope
Out of scope use cases (that are part of the Kubeframe/factory project):
- As a Partner (OEMs, ISVs), I want to install and pre-configure OpenShift with my hardware/software in my disconnected factory, while allowing further (minimal) reconfiguration of a subset of capabilities later at a different site by different set of users (end customer) [Embedded OpenShift].
- As an Infrastructure Admin at an Enterprise customer with multiple remote sites, I want to pre-provision OpenShift centrally prior to shipping and activating the clusters in remote sites.
Background, and strategic fit
- This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- The user has only access to the target nodes that will form the cluster and will boot them with the image presented locally via a USB stick. This scenario is common in sites with restricted access such as government infra where only users with security clearance can interact with the installation, where software is allowed to enter in the premises (in a USB, DVD, SD card, etc.) but never allowed to come back out. Users can't enter supporting devices such as laptops or phones.
- The user has access to the target nodes remotely to their BMCs (e.g. iDrac, iLo) and can map an image as virtual media from their computer. This scenario is common in data centers where the customer provides network access to the BMCs of the target nodes.
- We cannot assume that we will have access to a computer to run an installer or installer helper software.
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
References
Epic Goal
- As an OpenShift infrastructure owner, I need to be able to integrate the installation of my first on-premises OpenShift cluster with my automation flows and tools.
- As an OpenShift infrastructure owner, I must be able to provide the CLI tool with manifests that contain the definition of the cluster I want to deploy
- As an OpenShift Infrastructure owner, I must be able to get the validation errors in a programmatic way
- As an OpenShift Infrastructure owner, I must be able to get the events and progress of the installation in a programmatic way
- As an OpenShift Infrastructure owner, I must be able to retrieve the kubeconfig and OpenShift Console URL in a programmatic way
Why is this important?
- When deploying clusters with a large number of hosts and when deploying many clusters, it is common to require to automate the installations.
- Customers and partners usually use third party tools of their own to orchestrate the installation.
- For Telco RAN deployments, Telco partners need to repeatably deploy multiple OpenShift clusters in parallel to multiple sites at-scale, with no human intervention.
Scenarios
- Monitoring flow:
- I generate all the manifests for the cluster,
- call the CLI tool pointint to the manifests path,
- Obtain the installation image from the nodes
- Use my infrastructure capabilities to boot the image on the target nodes
- Use the tool to connect to assisted service to get validation status and events
- Use the tool to retrieve credentials and URL for the deployed cluster
Acceptance Criteria
- Backward compatibility between OCP releases with automation manifests (they can be applied to a newer version of OCP).
- Installation progress and events can be tracked programatically
- Validation errors can be obtained programatically
- Kubeconfig and console URL can be obtained programatically
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
References
User Story:
As a deployer, I want to be able to:
- Get the credentials for the cluster that is going to be deployed
so that I can achieve
- Checking the installed cluster for installation completion
- Connect and administer the cluster that gets installed
Currently the Assisted Service generates the credentials by running the ignition generation step of the oepnshift-installer. This is why the credentials are only retrievable from the REST API towards the end of the installation.
In the BILLI usage, which takes down assisted service before the installation is complete there is no obvious point at which to alert the user that they should retrieve the credentials. This means that we either need to:
- Allow the user to pass the admin key that will then get signed by the generated CA and replace the key that is made by openshift-installer (would mean new functionality in AI)
- Allow the key to be retrieved by SSH with the fleeting command from the node0 (after it has generated). The command should be able to wait until it is possible
- Have the possibility to POST it somewhere
Acceptance Criteria:
- The admin key is generated and usable to check for installation completeness
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview
The AWS-specific code added in OCPPLAN-6006 needs to become GA and with this we want to introduce a couple of Day2 improvements.
Currently the AWS tags are defined and applied at installation time only and saved in the infrastructure CRD's status field for further operator use, which in turn just add the tags during creation.
Saving in the status field means it's not included in Velero backups, which is a crucial feature for customers and Day2.
Thus the status.resourceTags field should be deprecated in favour of a newly created spec.resourceTags with the same content. The installer should only populate the spec, consumers of the infrastructure CRD must favour the spec over the status definition if both are supplied, otherwise the status should be honored and a warning shall be issued.
Being part of the spec, the behaviour should also tag existing resources that do not have the tags yet and once the tags in the infrastructure CRD are changed all the AWS resources should be updated accordingly.
On AWS this can be done without re-creating any resources (the behaviour is basically an upsert by tag key) and is possible without service interruption as it is a metadata operation.
Tag deletes continue to be out of scope, as the customer can still have custom tags applied to the resources that we do not want to delete.
Due to the ongoing intree/out of tree split on the cloud and CSI providers, this should not apply to clusters with intree providers (!= "external").
Once confident we have all components updated, we should introduce an end2end test that makes sure we never create resources that are untagged.
After that, we can remove the experimental flag and make this a GA feature.
Goals
- Inclusion in the cluster backups
- Flexibility of changing tags during cluster lifetime, without recreating the whole cluster
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
List any affected packages or components.
- Installer
- Cluster Infrastructure
- Storage
- Node
- NetworkEdge
- Internal Registry
- CCO
RFE-1101 described user defined tags for AWS resources provisioned by an OCP cluster. Currently user can define tags which are added to the resources during creation. These tags cannot be updated subsequently. The propagation of the tags is controlled using experimental flag. Before this feature goes GA we should define and implement a mechanism to exclude any experimental flags. Day2 operations and deletion of tags is not in the scope.
RFE-2012 aims to make the user-defined resource tags feature GA. This means that user defined tags should be updatable.
Currently the user-defined tags during install are passed directly as parameters of the Machine and Machineset resources for the master and worker. As a result these tags cannot be updated by consulting the Infrastructure resource of the cluster where the user defined tags are written.
The MCO should be changed such that during provisioning the MCO looks up the values of the tags in the Infrastructure resource and adds the tags during creation of the EC2 resources. The MCO should also watch the infrastructure resource for changes and when the resource tags are updated it should update the tags on the EC2 instances without restarts.
Acceptance Criteria:
e2e test where the ResourceTags are updated and then the test verifies that the tags on the ec2 instances are updated without restarts.now moved toCFE-179
Feature Overview
Much like core OpenShift operators, a standardized flow exists for OLM-managed operators to interact with the cluster in a specific way to leverage AWS STS authorization when using AWS APIs as opposed to insecure static, long-lived credentials. OLM-managed operators can implement integration with the CloudCredentialOperator in well-defined way to support this flow.
Goals:
Enable customers to easily leverage OpenShift's capabilities around AWS STS with layered products, for increased security posture. Enable OLM-managed operators to implement support for this in well-defined pattern.
Requirements:
- CCO gets a new mode in which it can reconcile STS credential request for OLM-managed operators
- A standardized flow is leveraged to guide users in discovering and preparing their AWS IAM policies and roles with permissions that are required for OLM-managed operators
- A standardized flow is defined in which users can configure OLM-managed operators to leverage AWS STS
- An example operator is used to demonstrate the end2end functionality
- Clear instructions and documentation for operator development teams to implement the required interaction with the CloudCredentialOperator to support this flow
Use Cases:
See Operators & STS slide deck.
Out of Scope:
- handling OLM-managed operator updates in which AWS IAM permission requirements might change from one version to another (which requires user awareness and intervention)
Background:
The CloudCredentialsOperator already provides a powerful API for OpenShift's cluster core operator to request credentials and acquire them via short-lived tokens. This capability should be expanded to OLM-managed operators, specifically to Red Hat layered products that interact with AWS APIs. The process today is cumbersome to none-existent based on the operator in question and seen as an adoption blocker of OpenShift on AWS.
Customer Considerations
This is particularly important for ROSA customers. Customers are expected to be asked to pre-create the required IAM roles outside of OpenShift, which is deemed acceptable.
Documentation Considerations
- Internal documentation needs to exists to guide Red Hat operator developer teams on the requirements and proposed implementation of integration with CCO and the proposed flow
- External documentation needs to exist to guide users on:
- how to become aware that the cluster is in STS mode
- how to become aware of operators that support STS and the proposed CCO flow
- how to become aware of the IAM permissions requirements of these operators
- how to configure an operator in the proposed flow to interact with CCO
Interoperability Considerations
- this needs to work with ROSA
- this needs to work with self-managed OCP on AWS
Market Problem
This Section: High-Level description of the Market Problem ie: Executive Summary
- As a customer of OpenShift layered products, I need to be able to fluidly, reliably and consistently install and use OpenShift layered product Kubernetes Operators into my ROSA STS clusters, while keeping a STS workflow throughout.
- As a customer of OpenShift on the big cloud providers, overall I expect OpenShift as a platform to function equally well with tokenized cloud auth as it does with "mint-mode" IAM credentials. I expect the same from the Kubernetes Operators under the Red Hat brand (that need to reach cloud APIs) in that tokenized workflows are equally integrated and workable as with "mint-mode" IAM credentials.
- As the managed services, including Hypershift teams, offering a downstream opinionated, supported and managed lifecycle of OpenShift (in the forms of ROSA, ARO, OSD on GCP, Hypershift, etc), the OpenShift platform should have as close as possible, native integration with core platform operators when clusters use tokenized cloud auth, driving the use of layered products.
- .
- As the Hypershift team, where the only credential mode for clusters/customers is STS (on AWS) , the Red Hat branded Operators that must reach the AWS API, should be enabled to work with STS credentials in a consistent, and automated fashion that allows customer to use those operators as easily as possible, driving the use of layered products.
Why it Matters
- Adding consistent, automated layered product integrations to OpenShift would provide great added value to OpenShift as a platform, and its downstream offerings in Managed Cloud Services and related offerings.
- Enabling Kuberenetes Operators (at first, Red Hat ones) on OpenShift for the "big3" cloud providers is a key differentiation and security requirement that our customers have been and continue to demand.
- HyperShift is an STS-only architecture, which means that if our layered offerings via Operators cannot easily work with STS, then it would be blocking us from our broad product adoption goals.
Illustrative User Stories or Scenarios
- Main success scenario - high-level user story
- customer creates a ROSA STS or Hypershift cluster (AWS)
- customer wants basic (table-stakes) features such as AWS EFS or RHODS or Logging
- customer sees necessary tasks for preparing for the operator in OperatorHub from their cluster
- customer prepares AWS IAM/STS roles/policies in anticipation of the Operator they want, using what they get from OperatorHub
- customer's provides a very minimal set of parameters (AWS ARN of role(s) with policy) to the Operator's OperatorHub page
- The cluster can automatically setup the Operator, using the provided tokenized credentials and the Operator functions as expected
- Cluster and Operator upgrades are taken into account and automated
- The above steps 1-7 should apply similarly for Google Cloud and Microsoft Azure Cloud, with their respective token-based workload identity systems.
- Alternate flow/scenarios - high-level user stories
- The same as above, but the ROSA CLI would assist with AWS role/policy management
- The same as above, but the oc CLI would assist with cloud role/policy management (per respective cloud provider for the cluster)
- ...
Expected Outcomes
This Section: Articulates and defines the value proposition from a users point of view
- See SDE-1868 as an example of what is needed, including design proposed, for current-day ROSA STS and by extension Hypershift.
- Further research is required to accomodate the AWS STS equivalent systems of GCP and Azure
- Order of priority at this time is
- 1. AWS STS for ROSA and ROSA via HyperShift
- 2. Microsoft Azure for ARO
- 3. Google Cloud for OpenShift Dedicated on GCP
Effect
This Section: Effect is the expected outcome within the market. There are two dimensions of outcomes; growth or retention. This represents part of the “why” statement for a feature.
- Growth is the acquisition of net new usage of the platform. This can be new workloads not previously able to be supported, new markets not previously considered, or new end users not previously served.
- Retention is maintaining and expanding existing use of the platform. This can be more effective use of tools, competitive pressures, and ease of use improvements.
- Both of growth and retention are the effect of this effort.
- Customers have strict requirements around using only token-based cloud credential systems for workloads in their cloud accounts, which include OpenShift clusters in all forms.
- We gain new customers from both those that have waited for token-based auth/auth from OpenShift and from those that are new to OpenShift, with strict requirements around cloud account access
- We retain customers that are going thru both cloud-native and hybrid-cloud journeys that all inevitably see security requirements driving them towards token-based auth/auth.
- Customers have strict requirements around using only token-based cloud credential systems for workloads in their cloud accounts, which include OpenShift clusters in all forms.
References
As an engineer I want the capability to implement CI test cases that run at different intervals, be it daily, weekly so as to ensure downstream operators that are dependent on certain capabilities are not negatively impacted if changes in systems CCO interacts with change behavior.
Acceptance Criteria:
Create a stubbed out e2e test path in CCO and matching e2e calling code in release such that there exists a path to tests that verify working in an AWS STS workflow.
Feature Overview
Customers are asking for improvements to the upgrade experience (both over-the-air and disconnected). This is a feature tracking epics required to get that work done.
Goals
- Have an option to do upgrades in more discrete steps under admin control. Specifically, these steps are:
- Control plane upgrade
- Worker nodes upgrade
- Workload enabling upgrade (i..e. Router, other components) or infra nodes
- Better visibility into any errors during the upgrades and documentation of what they error means and how to recover.
- An user experience around an end-2-end back-up and restore after a failed upgrade
OTA-810- Better Documentation:- Backup procedures before upgrades.
- More control over worker upgrades (with tagged pools between user Vs admin)
- The kinds of pre-upgrade tests that are run, the errors that are flagged and what they mean and how to address them.
- Better explanation of each discrete step in upgrades, and what each CVO Operator is doing and potential errors, troubleshooting and mitigating actions.
References
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Provide a one click option to perform an upgrade which pauses all non master pools
Why is this important?
- Customers are increasingly asking that the overall upgrade is broken up into more digestible pieces
- This is the limit of what's possible today
- R&D work will be done in the future to allow for further bucketing of upgrades into Control Plane, Worker Nodes, and Workload Enabling components (ie: router) That will however take much more consideration and rearchitecting
Scenarios
- An admin selecting their upgrade is offered two options "Upgrade Cluster" and "Upgrade Control Plane"
-
- If the admin selects Upgrade Cluster they get the pre 4.10 behavior
- If the admin selects Upgrade Control Plane all non master pools are paused and an upgrade is initiated
- A tooltip should clarify what the difference between the two are
- The pool progress bars should indicate pause/unpaused status, non master pools should allow for unpausing
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- While this epic doesn't specifically target upgrading from 4.N to 4.N+1 to 4.N+2 with non master pools paused it would fundamentally enable that and it would simplify the UX described in Paused Worker Pool Upgrades
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
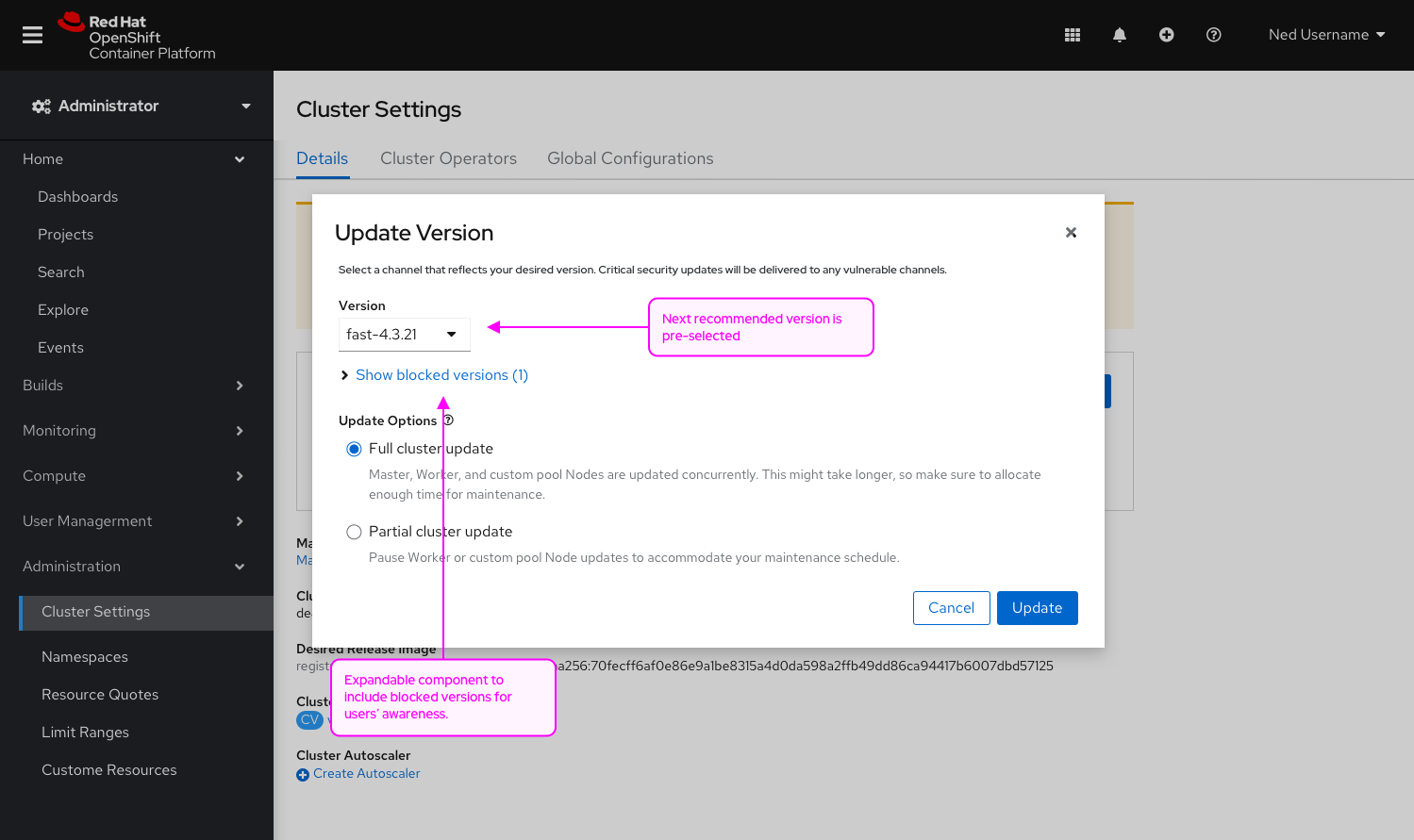
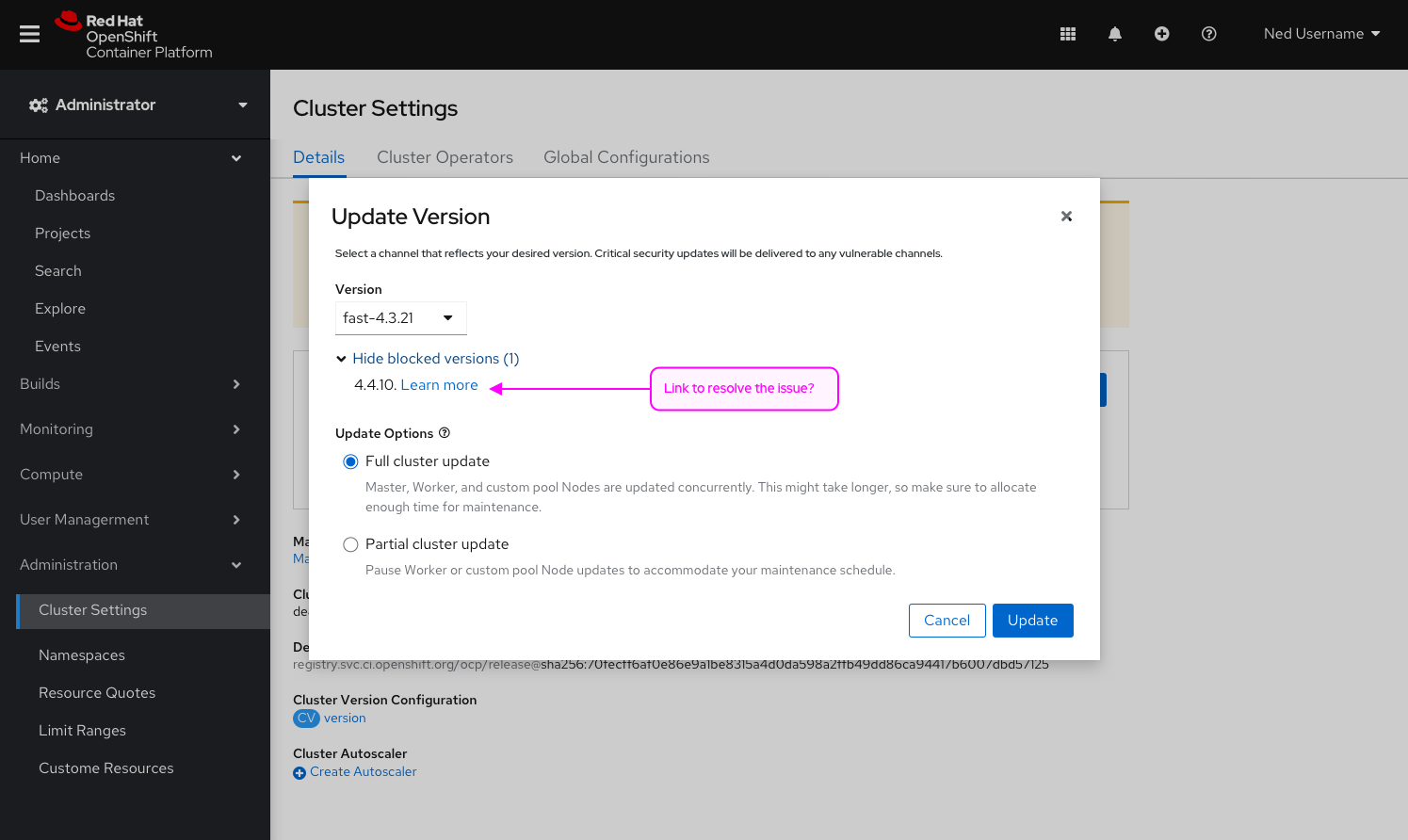
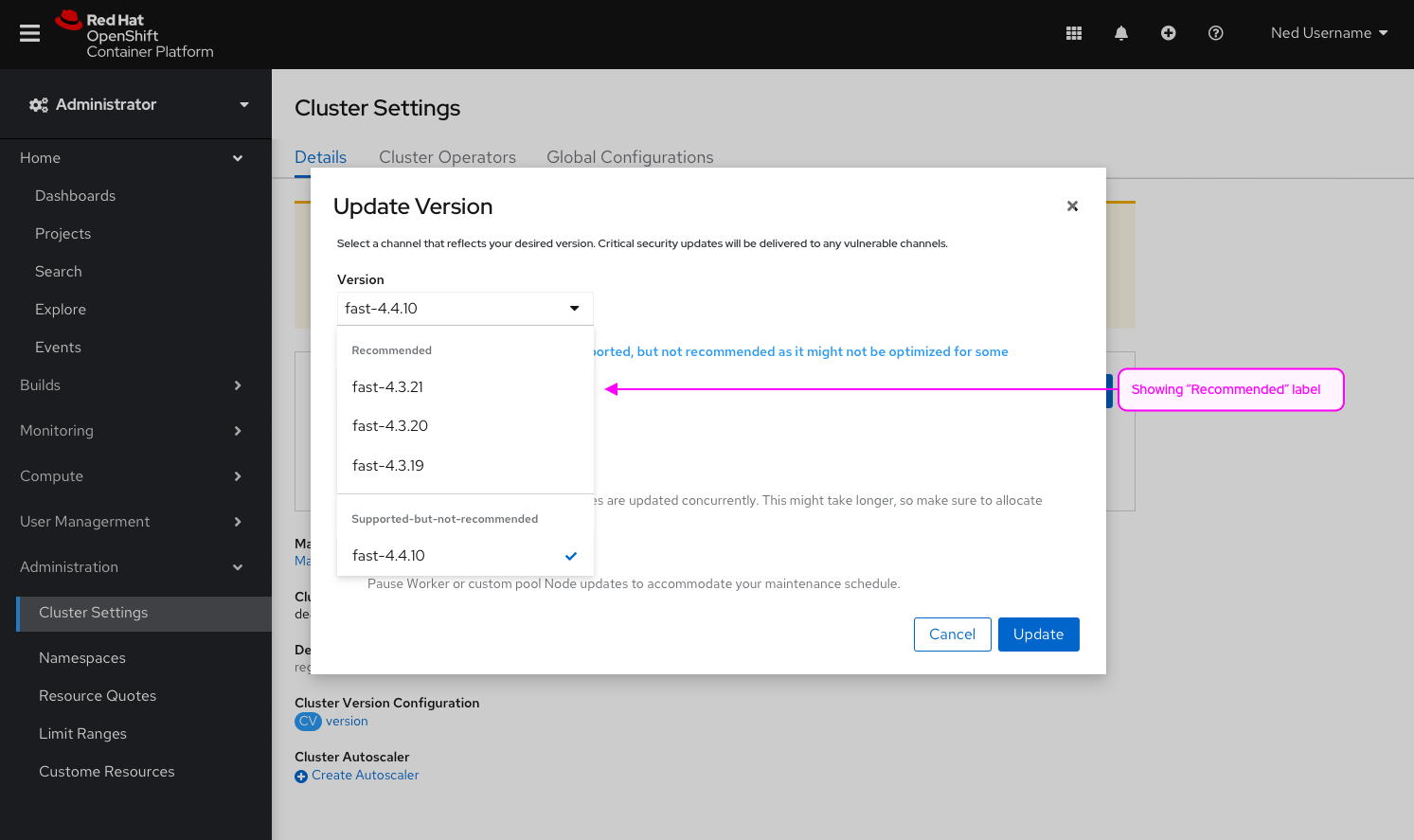
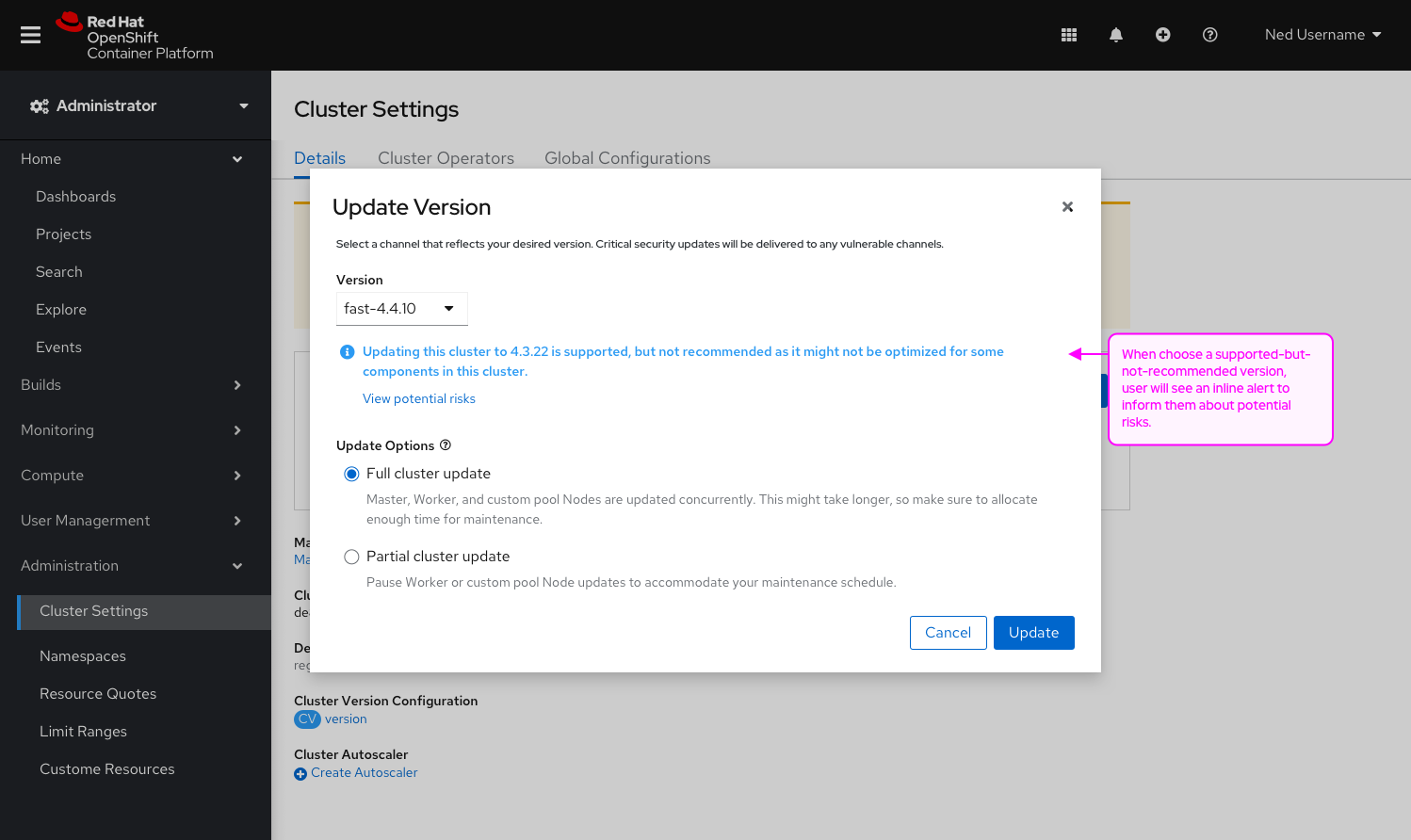
Goal
Improve the UX on the machine config pool page to reflect the new enhancements on the cluster settings that allows users to select the ability to update the control plane only.
Background
Currently in the console, users only have the ability to complete a full cluster upgrade. For many customers, upgrades take longer than what their maintenance window allows. Users need the ability to upgrade the control plane independently of the other worker nodes.
Ex. Upgrades of huge clusters may take too long so admins may do the control plane this weekend, worker-pool-A next weekend, worker-pool-B the weekend after, etc. It is all at a pool level, they will not be able to choose specific hosts.
Requirements
- Changes to the table:
- Remove "Updated, updating and paused" columns. We could also consider adding column management to this table and hide those columns by default.
- Add "Update status" as a column, and surface the same status on cluster settings. Not true or false values but instead updating, paused, and up to date.
- Surface the update action in the table row.
- Add an inline alert that lets users know there is a 60 day window to update all worker pools. In the alert, include the sentiment that worker pools can remain paused as long as is normally safe, which means until certificate rotation becomes critical which is at about 60 days. The admin would be advised to unpause them in order to complete the full upgrade. If the MCPs are paused, the certification rotation does not happen, which causes the cluster to become degraded and causes failure in multiple 'oc' commands, including but not limited to 'oc debug', 'oc logs', 'oc exec' and 'oc attach'. (Are we missing anything else here?) Add the same alert logic to this page as the cluster settings:
- From day 60 to day 10 use the default inline alert.
- From day 10 to day 3 use the warning inline alert.
- From day 3 to 0 use the critical alert and continue to persist until resolved.
Design deliverables:
Goal
Add the ability to choose between a full cluster upgrade (which exists today) or control plane upgrade (which will pause all worker pools) in the console.
Background
Currently in the console, users only have the ability to complete a full cluster upgrade. For many customers, upgrades take longer than what their maintenance window allows. Users need the ability to upgrade the control plane independently of the other worker nodes.
Ex. Upgrades of huge clusters may take too long so admins may do the control plane this weekend, worker-pool-A next weekend, worker-pool-B the weekend after, etc. It is all at a pool level, they will not be able to choose specific hosts.
Requirements
- Changes to the Update modal:
- Add the ability to choose between a cluster upgrade and a control plane upgrade (the design does not default to a selection but rather disables the update button to force the user to make a conscious decision)
- link out to documentation to learn more about update strategies
- Changes to the in progress check list:
- Add a status above the worker pool section to let users know that all worker pools are paused and an action to resume all updates
- Add a "resume update" button for each worker pool entry
- Changes to the update status:
- When all master pools are updated successfully, change the status from what we have today "Up to date" to something like "Control plane up to date - all worker pools paused"
- Add an inline alert that lets users know there is a 60 day window to update all worker pools. In the alert, include the sentiment that worker pools can remain paused as long as is normally safe, which means until certificate rotation becomes critical which is at about 60 days. The admin would be advised to unpause them in order to complete the full upgrade. If the MCPs are paused, the certification rotation does not happen, which causes the cluster to become degraded and causes failure in multiple 'oc' commands, including but not limited to 'oc debug', 'oc logs', 'oc exec' and 'oc attach'. (Are we missing anything else here?) Inline alert logic:
- From day 60 to day 10 use the default alert.
- From day 10 to day 3 use the warning alert.
- From day 3 to 0 use the critical alert and continue to persist until resolved.
Design deliverables:
OCP/Telco Definition of Done
Feature Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Feature --->
<--- Remove the descriptive text as appropriate --->
Feature Overview
- As RH OpenShift Product Owners, we want to enable new providers/platforms/service with varying levels of capabilities and integration with minimal reliance on OpenShift Engineering.
- As a new provider/platform partner, I want to enable my solution (hardware and/or software) with OpenShift with minimal effort.
Problem
- It is currently challenging for us to enable new platforms / providers without taking the heavy burden on doing the platform specific development ourselves.
Goals
- We want to enable the long-tail new platforms/providers to expand our reach into new markets and/or support new use cases.
- We want to remove strict dependencies we have on Engineering teams to review, support and test new providers.
- We want to lower the effort required for onboarding new platforms/providers.
- We want to enable new platform/providers to self-certify.
- We want to define tiered model for provider/platform integration that delineates ownership and responsibilities throughout new provider/platform development lifecycle and support model.
- We want to reduce time to onboard new provider/platform – ideally to a single release.
- We want to maintain consistent customer experience across all providers/platforms.
Requirements
- Step-by-step guide on how to add a new platform/provider for each tier
- Certification tool for partner to self-certify
- Certification tool results for (at least) each Y/minor release submitted by partner to Red Hat for acknowledgement
- DCI program to enable partners to run CI with OpenShift on their platform
- Well documented, accessible, and up-to-date test suites for providing the test coverage of the partner
- CI includes upgrade testing of OpenShift with partner's components
- Partner component upgrade failure should not block OpenShift upgrade
- Partner code is available in repositories in the openshift org on github with an open source license compatible with OpenShift
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
References
- [ Notes - OpenShift Everywhere - Onboarding new providers/platforms|https://www.google.com/url?q=[https://docs.google.com/document/d/1M1zLG2-wmkeCWTS8omN5G8vsDKvDeZfmegsi7cCVh-U/edit?usp%3Dsharing&sa=D&source=calendar&ust=1641920246517943&usg=AOvVaw2ZIl_XuE7OsSr4wCmRjOp3]]
- OKD Installer Architecture Brainstorming Working Group Meeting Minutes
- New-Platform Documentation Working Group Meeting Minutes
Running the OPCT with the latest version (v0.1.0) on OCP 4.11.0, the openshift-tests is reporting an incorrect counter for the "total" field.
In the example below, after the 1127th test, the total follows the same counter of executed. I also would assume that the total is incorrect before that point as the test continues the execution increases both counters.
openshift-tests output format: [failed/executed/total]
started: (0/1126/1127) "[sig-storage] PersistentVolumes-expansion loopback local block volume should support online expansion on node [Suite:openshift/conformance/parallel] [Suite:k8s]" passed: (38s) 2022-08-09T17:12:21 "[sig-storage] In-tree Volumes [Driver: nfs] [Testpattern: Dynamic PV (default fs)] provisioning should provision storage with mount options [Suite:openshift/conformance/parallel] [Suite:k8s]" started: (0/1127/1127) "[sig-storage] In-tree Volumes [Driver: local][LocalVolumeType: tmpfs] [Testpattern: Generic Ephemeral-volume (block volmode) (late-binding)] ephemeral should support two pods which have the same volume definition [Suite:openshift/conformance/parallel] [Suite:k8s]" passed: (6.6s) 2022-08-09T17:12:21 "[sig-storage] Downward API volume should provide container's memory request [NodeConformance] [Conformance] [Suite:openshift/conformance/parallel/minimal] [Suite:k8s]" started: (0/1128/1128) "[sig-storage] In-tree Volumes [Driver: cinder] [Testpattern: Dynamic PV (immediate binding)] topology should fail to schedule a pod which has topologies that conflict with AllowedTopologies [Suite:openshift/conformance/parallel] [Suite:k8s]" skip [k8s.io/kubernetes@v1.24.0/test/e2e/storage/framework/testsuite.go:116]: Driver local doesn't support GenericEphemeralVolume -- skipping Ginkgo exit error 3: exit with code 3 skipped: (400ms) 2022-08-09T17:12:21 "[sig-storage] In-tree Volumes [Driver: local][LocalVolumeType: tmpfs] [Testpattern: Generic Ephemeral-volume (block volmode) (late-binding)] ephemeral should support two pods which have the same volume definition [Suite:openshift/conformance/parallel] [Suite:k8s]" started: (0/1129/1129) "[sig-storage] In-tree Volumes [Driver: emptydir] [Testpattern: Dynamic PV (default fs)] capacity provides storage capacity information [Suite:openshift/conformance/parallel] [Suite:k8s]"
OPCT output format [executed/total (failed failures)]
Tue, 09 Aug 2022 14:12:13 -03> Global Status: running JOB_NAME | STATUS | RESULTS | PROGRESS | MESSAGE openshift-conformance-validated | running | | 1112/1127 (0 failures) | status=running openshift-kube-conformance | complete | | 352/352 (0 failures) | waiting for post-processor... Tue, 09 Aug 2022 14:12:23 -03> Global Status: running JOB_NAME | STATUS | RESULTS | PROGRESS | MESSAGE openshift-conformance-validated | running | | 1120/1127 (0 failures) | status=running openshift-kube-conformance | complete | | 352/352 (0 failures) | waiting for post-processor... Tue, 09 Aug 2022 14:12:33 -03> Global Status: running JOB_NAME | STATUS | RESULTS | PROGRESS | MESSAGE openshift-conformance-validated | running | | 1139/1139 (0 failures) | status=running openshift-kube-conformance | complete | | 352/352 (0 failures) | waiting for post-processor... Tue, 09 Aug 2022 14:12:43 -03> Global Status: running JOB_NAME | STATUS | RESULTS | PROGRESS | MESSAGE openshift-conformance-validated | running | | 1185/1185 (0 failures) | status=running openshift-kube-conformance | complete | | 352/352 (0 failures) | waiting for post-processor... Tue, 09 Aug 2022 14:12:53 -03> Global Status: running JOB_NAME | STATUS | RESULTS | PROGRESS | MESSAGE openshift-conformance-validated | running | | 1188/1188 (0 failures) | status=running openshift-kube-conformance | complete | | 352/352 (0 failures) | waiting for post-processor...
OCP/Telco Definition of Done
Feature Template descriptions and documentation.
Feature Overview
- Connect OpenShift workloads to Google services with Google Workload Identity
Enable customers to access Google services from workloads on OpenShift clusters using Google Workload Identity (aka WIF)
https://cloud.google.com/kubernetes-engine/docs/concepts/workload-identity
Goals
- Customers want to be able to manage and operate OpenShift on Google Cloud Platform with workload identity, much like they do with AWS + STS or Azure + workload identity.
- Customers want to be able to manage and operate operators and customer workloads on top of OCP on GCP with workload identity.
Requirements
- Add support to CCO for the Installation and Upgrade using both UPI and IPI methods with GCP workload identity.
- Support install and upgrades for connected and disconnected/restriction environments.
- Support the use of Operators with GCP workload identity with minimal friction.
- Support for HyperShift and non-HyperShift clusters.
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Epic Goal
- Complete the implementation for GCP workload identity, including support and documentation.
Why is this important?
- Many customers want to follow best security practices for handling credentials.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
Open questions:
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
We need to ensure following things in the openshift operators
1) Make sure to operator uses v0.0.0-20210218202405-ba52d332ba99 or later version of the golang.org/x/oauth2 module
2) Mount the oidc token in the operator pod, this needs to go in the deployment. We have done it for cluster-image-registry-operator here
3) For workload identity to work, gco credentials that the operator pod uses should be of external_account type (not service_account). The external_account credentials type have path to oidc token along, url of the service account to impersonate along with other details. These type of credentials can be generated from gcp console or programmatically (supported by ccoctl). The operator pod can then consume it from a kube secret. Make appropriate code changes to the operators so that can consume these new credentials
Following repos need one or more of above changes
- https://github.com/openshift/cloud-credential-operator
- https://github.com/openshift/cluster-image-registry-operator
- https://github.com/openshift/cluster-ingress-operator
- https://github.com/openshift/cluster-storage-operator
- https://github.com/openshift/cluster-api-provider-gcp
- https://github.com/openshift/gcp-pd-csi-driver
- https://github.com/openshift/machine-api-operator
- https://github.com/openshift/gcp-pd-csi-driver-operator
- https://github.com/openshift/image-registry
- https://github.com/openshift/docker-distribution
Feature Overview
Enable sharing ConfigMap and Secret across namespaces
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| Secrets and ConfigMaps can get shared across namespaces | YES |
Questions to answer…
NA
Out of Scope
NA
Background, and strategic fit
Consumption of RHEL entitlements has been a challenge on OCP 4 since it moved to a cluster-based entitlement model compared to the node-based (RHEL subscription manager) entitlement mode. In order to provide a sufficiently similar experience to OCP 3, the entitlement certificates that are made available on the cluster (OCPBU-93) should be shared across namespaces in order to prevent the need for cluster admin to copy these entitlements in each namespace which leads to additional operational challenges for updating and refreshing them.
Documentation Considerations
Questions to be addressed:
* What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
* Does this feature have doc impact?
* New Content, Updates to existing content, Release Note, or No Doc Impact
* If unsure and no Technical Writer is available, please contact Content Strategy.
* What concepts do customers need to understand to be successful in [action]?
* How do we expect customers will use the feature? For what purpose(s)?
* What reference material might a customer want/need to complete [action]?
* Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
* What is the doc impact (New Content, Updates to existing content, or Release Note)?
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Deliver the Projected Resources CSI driver via the OpenShift Payload
Why is this important?
- Projected resource shares will be a core feature of OpenShift. The share and CSI driver have multiple use cases that are important to users and cluster administrators.
- The use of projected resources will be critical to distributing Simple Content Access (SCA) certificates to workloads, such as Deployments, DaemonSets, and OpenShift Builds.
Scenarios
As a developer using OpenShift
I want to mount a Simple Content Access certificate into my build
So that I can access RHEL content within a Docker strategy build.
As a application developer or administrator
I want to share credentials across namespaces
So that I don't need to copy credentials to every workspace
Acceptance Criteria
- OCP conformance suite must ensure that the projected resource CSI driver is installed on every OpenShift deployment.
- OCP build suite tests that projected resource CSI driver volumes can be added to builds. Only if builds support inline CSI volumes.
- Release Technical Enablement - Docs and demos on how to create a Projected Resource share and add it as a volume to workloads. A special use case for adding RHEL entitlements to builds should be included.
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story
As an OpenShift engineer
I want to know which clusters are using the Shared Resource CSI Driver
So that I can be proactive in supporting customers who are using this tech preview feature
Acceptance Criteria
- Key metrics for the shared resource CSI driver are exported to Telemeter via the cluster monitoring operator.
Docs Impact
None - metrics exported to telemetry are not formally documented.
QE Impact
QE can verify that the query/recording rule for cluster monitoring operator returns data if the cluster has the Shared Resource CSI driver installed and utilizes a SharedSecret or SharedConfigMap in a pod/workload.
PX Impact
Insights rules can potentially be created off of these exported metrics. This would allow CEE to identify which clusters are using SharedSecrets or SharedConfigMaps, especially if we are exporting mount failure metrics.
Notes
To implement, a prometheus query/recording rule needs to be added to the cluster monitoring operator. Once approved by the monitoring team, the metric data will be available on DataHub once 4.10 clusters are installed with the updated version of the monitoring operator.
User Story
As a cluster admin
I want the cluster storage operator to install the shared resources CSI driver
So that I can test the shared resources CSI driver on my cluster
Acceptance Criteria
- Cluster storage operator uses image references to resolve the csi-driver-shared-resource-operator and all images needed to deploy the csi driver.
- Shared resources CSI driver is installed when the cluster enables the CSIDriverSharedResources feature gate, OR
- Shared resource CSI driver is installed when the cluster enables the TechPreviewNoUpgrade feature set
- CI ensures that if the TechPreviewNoUpgrade feature set is enabled on the cluster, the shared resource CSI driver is deployed and functions correctly.
Docs Impact
Docs will need to identify how to install the shared resources CSI driver (by enabling the tech preview feature set)
Notes
Tasks:
- Add the Share APIs (SharedSecret, SharedConfigMap) to openshift/api
- Generate clients in openshift/client-go for Share APIs
- Update the CSI driver name used in the enum for the ClusterCSIDriver custom resource.
- Generate custom resource definitions and include it in the deployment YAMLs for the shared resource operator
- Add YAML deployment manifests for the shared resource operator to the cluster storage operator (include necessary RBAC)
- Ensure cluster storage operator has permission to create custom resource definitions
- Enhance the cluster storage operator to install the shared resource CSI driver only when the cluster enables the CSIDriverSharedResources feature gate
Note that to be able to test all of this on any cloud provider, we need STOR-616 to be implemented. We can work around this by making the CSI driver installable on AWS or GCP for testing purposes.
The cluster storage operator has cluster-admin permissions. However, no other CSI driver managed by the operator includes a CRD for its API.
Feature Overview (aka. Goal Summary)
Upstream Kuberenetes is following other SIGs by moving it's intree cloud providers to an out of tree plugin format, Cloud Controller Manager, at some point in a future Kubernetes release. OpenShift needs to be ready to action this change
Goals (aka. expected user outcomes)
Bring together all the cloud controller managers (AWS, GCP, Azure), complete testing and prepare for final GA
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Prepare the Cluster Cloud Controller Manager Operator (CCCMO) component, introduced in 4.9 for GA
Why is this important?
- We must ensure that the component is stable before we can declare the product GA
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Initial work was started there: https://github.com/lobziik/cluster-cloud-controller-manager-operator/pull/1/files
Need to isolate provider specific code in respective packages and introduce interface to leverage it (regular and bootstrap manifests rendering should be there atm)
DoD:
- Introduce templating logic to replace existing substitution mixture
- Isolate templating logic so that this is transparent to the core of the CCCMO
- Improve testing of the substitution
Feature Overview
This Feature is a general "catch all" for the time being. There are a number of existing priorities from Q1 that should be aligned with existing priorities below but if not, assign to this feature as needed.
Goals
In order to get a better overall portfolio view, we'll leverage this Feature to gather work that doesn't fall into other existing priorities on this board. As this list grows, the portfolio priority grooming team will look to split out or handle appropriately.
Requirements
A list of specific needs or objectives that a Feature must deliver to satisfy the Feature. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| requirement | Notes | isMvp |
|---|---|---|
(Optional) Use Cases
< How will the user interact with this feature? >
< Which users will use this and when will they use it? >
< Is this feature used as part of current user interface? >
Out of Scope
Background, and strategic fit
< What does the person writing code, testing, documenting need to know? >
Assumptions
< Are there assumptions being made regarding prerequisites and dependencies?>
< Are there assumptions about hardware, software or people resources?>
Customer Considerations
< Are there specific customer environments that need to be considered (such as working with existing h/w and software)?>
Documentation Considerations
< What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)? >
<What does success look like?>
< Does this feature have doc impact? Possible values are: New Content, Updates to existing content, Release Note, or No Doc Impact?>
<If unsure and no Technical Writer is available, please contact Content Strategy. If yes, complete the following.>
- <What concepts do customers need to understand to be successful in [action]?>
- <How do we expect customers will use the feature? For what purpose(s)?>
- <What reference material might a customer want/need to complete [action]?>
- <Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available. >
- <What is the doc impact (New Content, Updates to existing content, or Release Note)?>
Questions
| Question | Outcome |
Problem:
Console provides support UI for operators which is dynamically enabled when the operator is installed; by using feature flags against presence of CRDs. While operators have their own release cadence separately from OpenShift which makes for alignment of UI to API difficult. As new features are released for the operator, the UI becomes out of sync with APIs and customers must wait till the following OpenShift release to get any new UI.
Goal:
- Create an extensibility mechanism which allows Red Hat operators to build and package their own UI that extends the console.
- Make console extensible in areas required to support the needs of contributing plugins.
Why is it important?
- Allows an operator to maintain their own UI and release at their own cadence.
- Alleviates the pressure on console to deliver UI features for multiple operators within a release.
Use cases:
- Serverless / Pipelines / Helm to contribute resource details pages, import flows, topology visuals etc...
Acceptance criteria:
- Red Hat Operator can build their own UI which is deployed alongside the operator and extend the dev-console
- objective is to get to a point where it is possible to accomplish this however code will not be moved to a separate repository, nor deployed by an operator
- New extensions for console to allow operators to extend the various areas of console needed in order to provide the proper user experience.
- Enable operators to override the static built in support, and supply their own UI
Dependencies (External/Internal):
Design Artifacts:
Console extensions:
https://docs.google.com/document/d/1HW5_cl6cOX5P14PQN-1_8c60o9dMY6HbFDRftH6aTno/edit
Dynamic Plugins:
https://docs.google.com/document/d/19BAFo_8BtMZVvKsU-bE61bZpSydeYONkCMWntMU9NgE/edit
Enhancement proposal:
https://github.com/openshift/enhancements/pull/441
Exploration:
Note:
- plugin framework covered by another epic
- out of scope:
- moving plugins to separate git repository